
Community Over Code (Europe) 2024
Published: 2024-06-17 05:00PM
This year’s European edition of the ASF conference, Community Over Code EU, featured three in-person days of sessions (June 3-5) in Bratislava, Slovakia, including a Groovy track on the last day.
|
Note
|
The presentation slides and audio/video (where available) are still being added onto the conference site. If additional material becomes available, this post will be updated with links to the additional content. |
This post gives a short trip report on the conference mostly focussed on the Groovy track.
The Conference, Venue, and Host city
The conference was hosted at the Radisson Blu Carlton in Bratislava, Slovakia. The facilities were great, and it was a great city to visit.






Kudos to all involved for making the event a fruitful and rewarding one!
Highlights from the Groovy BoF and Groovy Track
We had a very engaging Birds-of-a-Feather (BoF) session with various users of the Groovy programming language including a large contingent from the Apache OFBiz project. We also discussed some of the reasons why Groovy is still a compelling language choice in 2024.
Why use Groovy in 2024?
This talk looked at some of the compelling reasons for using Groovy today.

Some highlights:
-
Groovy’s 80+ AST transforms allow you to write concise declarative style code. As one example, here’s an example of a deeply immutable
Bookclass with additional generated code for comparators (sorting), custom serialization and deserialization, and some special JavaBean index handling code:
-
Groovy’s 2000+ extension methods enrich the Java class libraries with additional functionality. As one example, primitive array extensions speed up certain operations where you might otherwise use streams:

-
Groovy’s operator overloading and extensible tooling greatly simplifies use of the libraries and APIs that Java programmers are familiar with. Here’s an example of using Apache Commons Math:
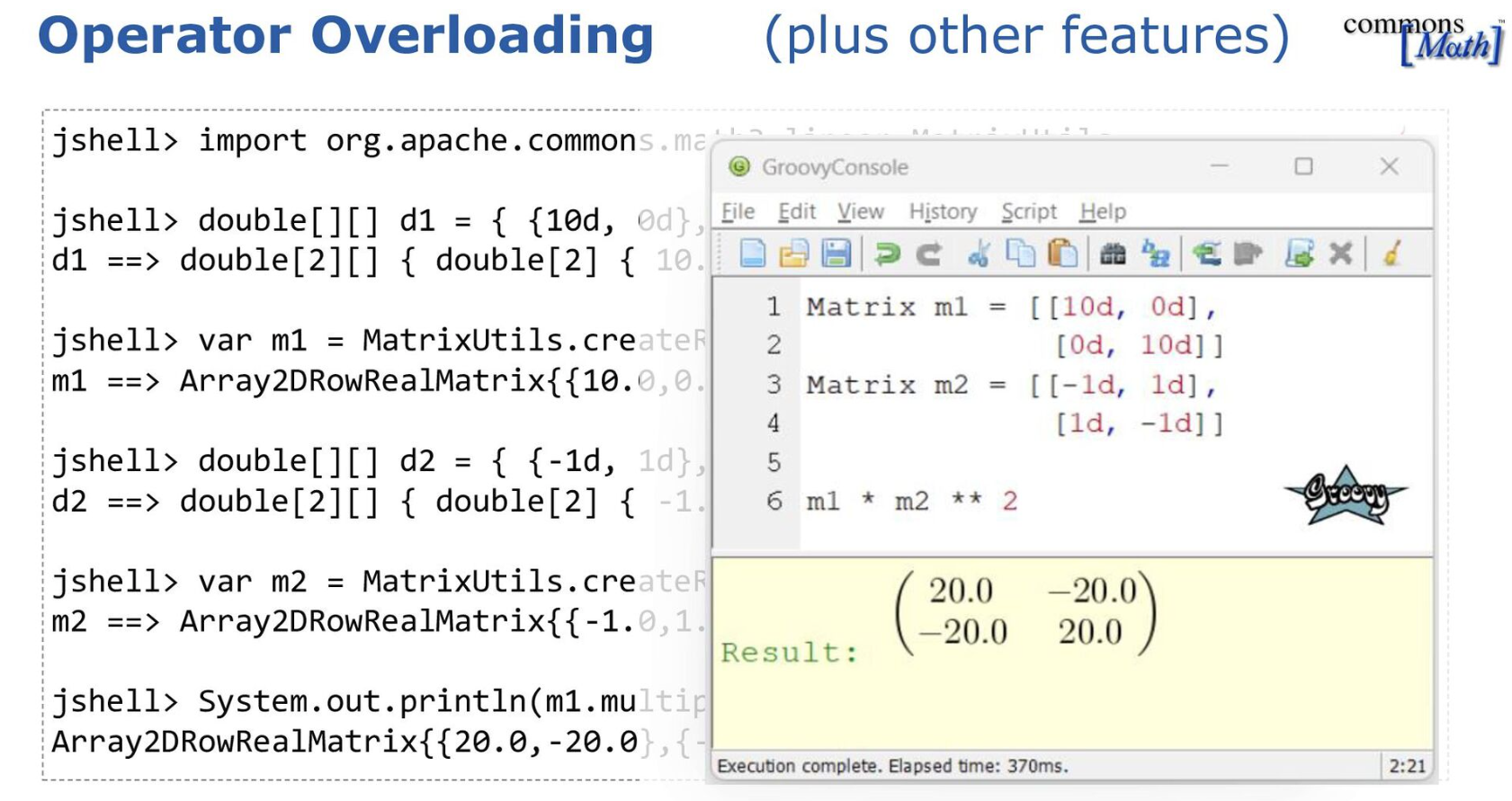
-
Groovy has excellent scripting and domain specific language (DSL) support. As one example, in about 10 lines of code, you can write a statically-typed DSL for working with Roman numerals. Once the DSL is defined, you can use it in scripts like this:
assert [LVII + LVII, V * III, V ** II, IV..(V+I), [X, V, I].sort()] == [ cxiv, xv, xxv, iv..vi, [i, v, x] ]Invalid roman numerals are detected at compile-time:

Check out the slide deck for more information.
Classifying Iris flowers with Groovy, Deep Learning, and GraalVM
This talk looked at the machine language problem of classification using a classic Iris flowers dataset.

Highlights:
-
Classification predicts the class of something using models trained on measured features given a known class:
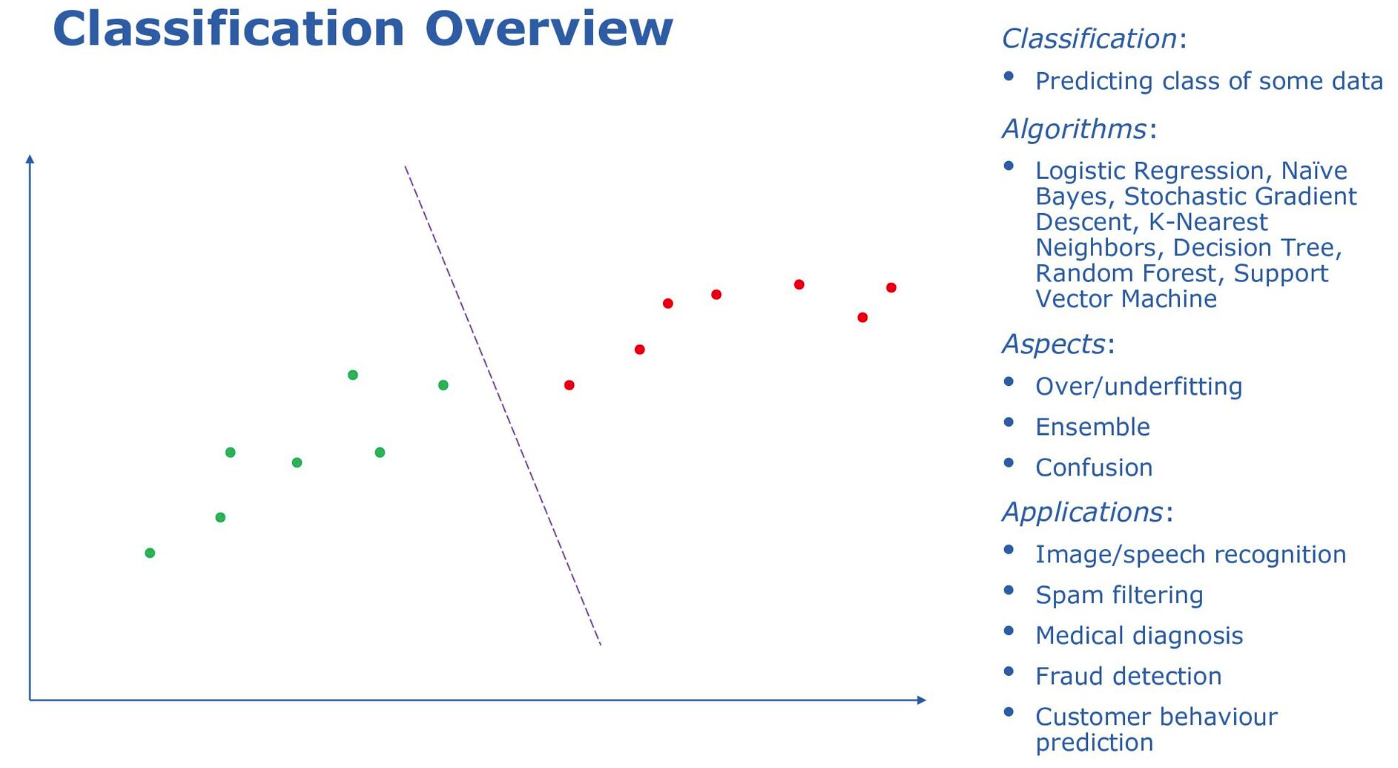
-
The case study uses a well-known Iris dataset. The measured features are sepal width and length, and petal width and length:

-
First, a number of classic algorithms for doing classification were examined including the Naïve Bayes algorithm, here using the Weka data science library:
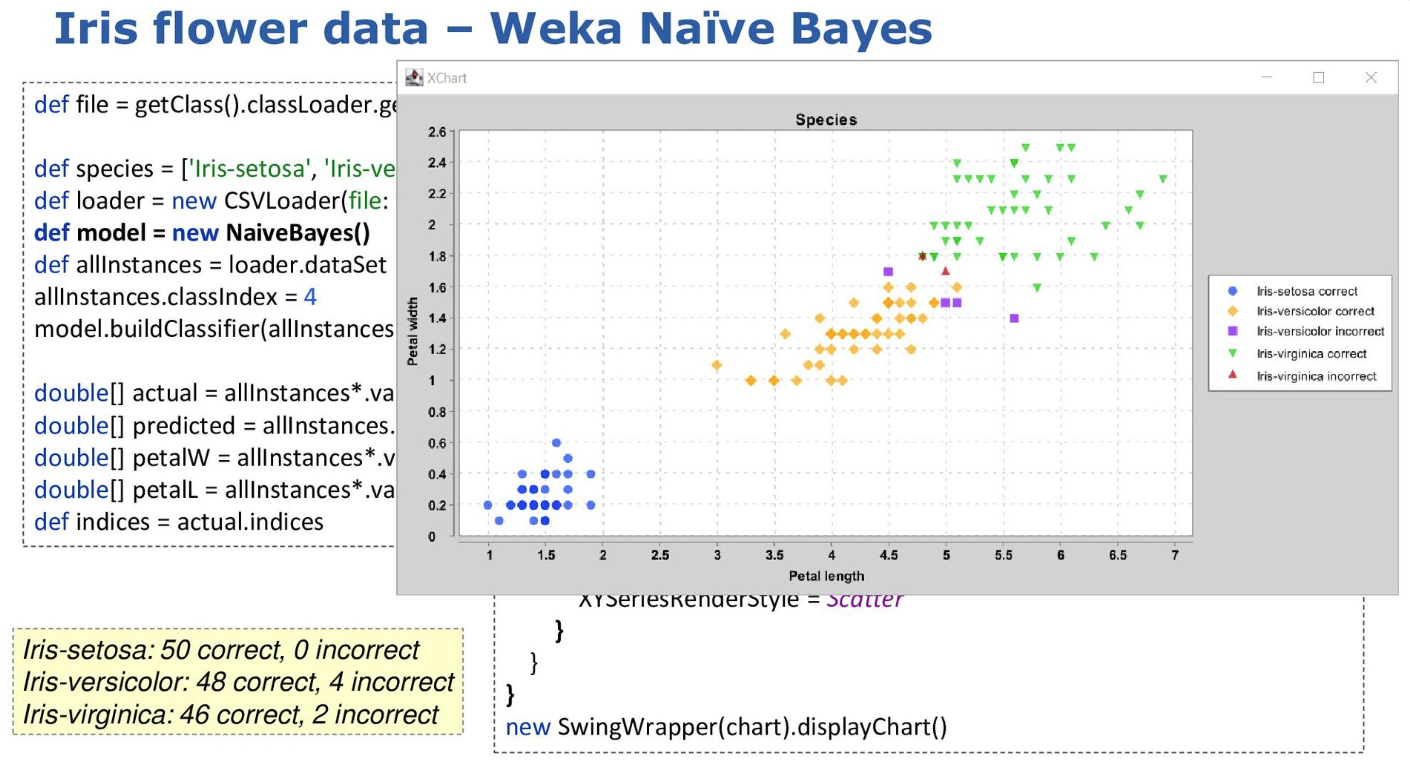
-
Then neural networks are explained. A potential network for the case study is shown here:
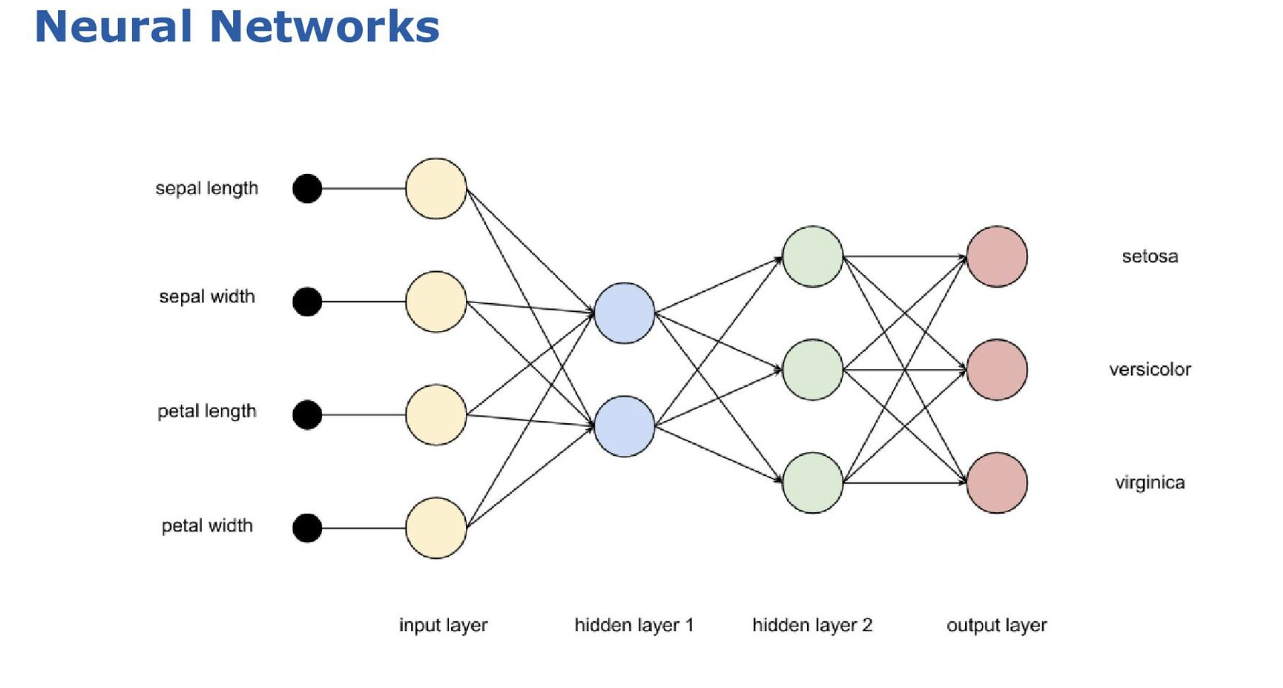
-
Each node acts like a neuron in the human brain:
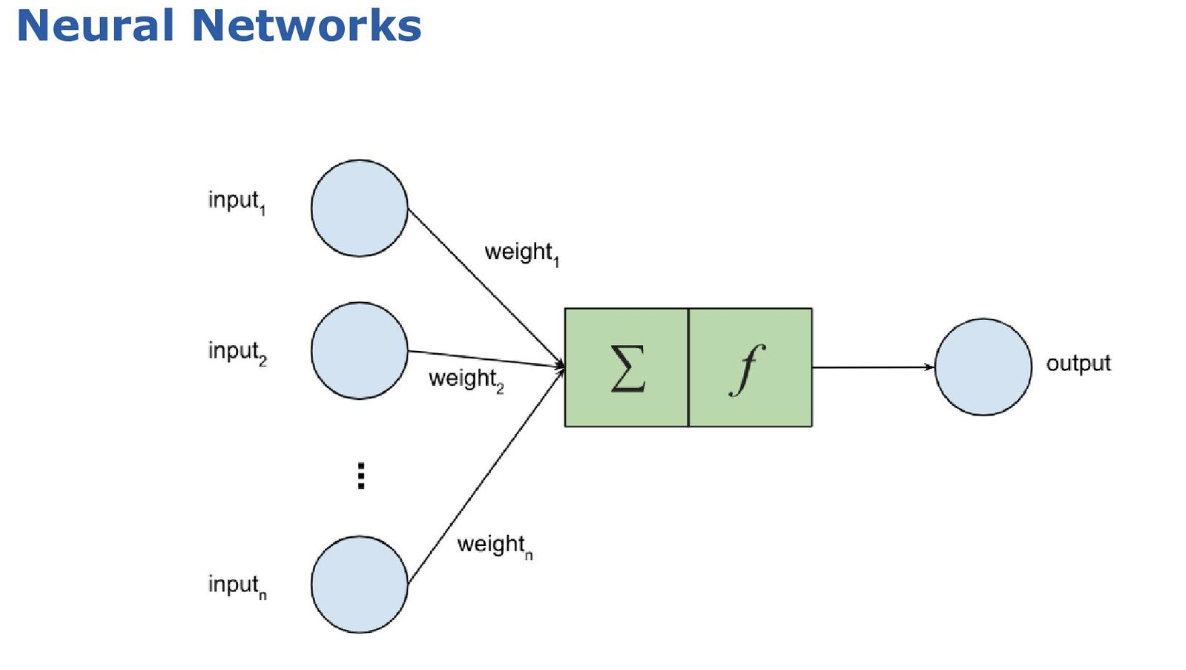
-
Several libraries for deep learning were discussed including Deep Netts:
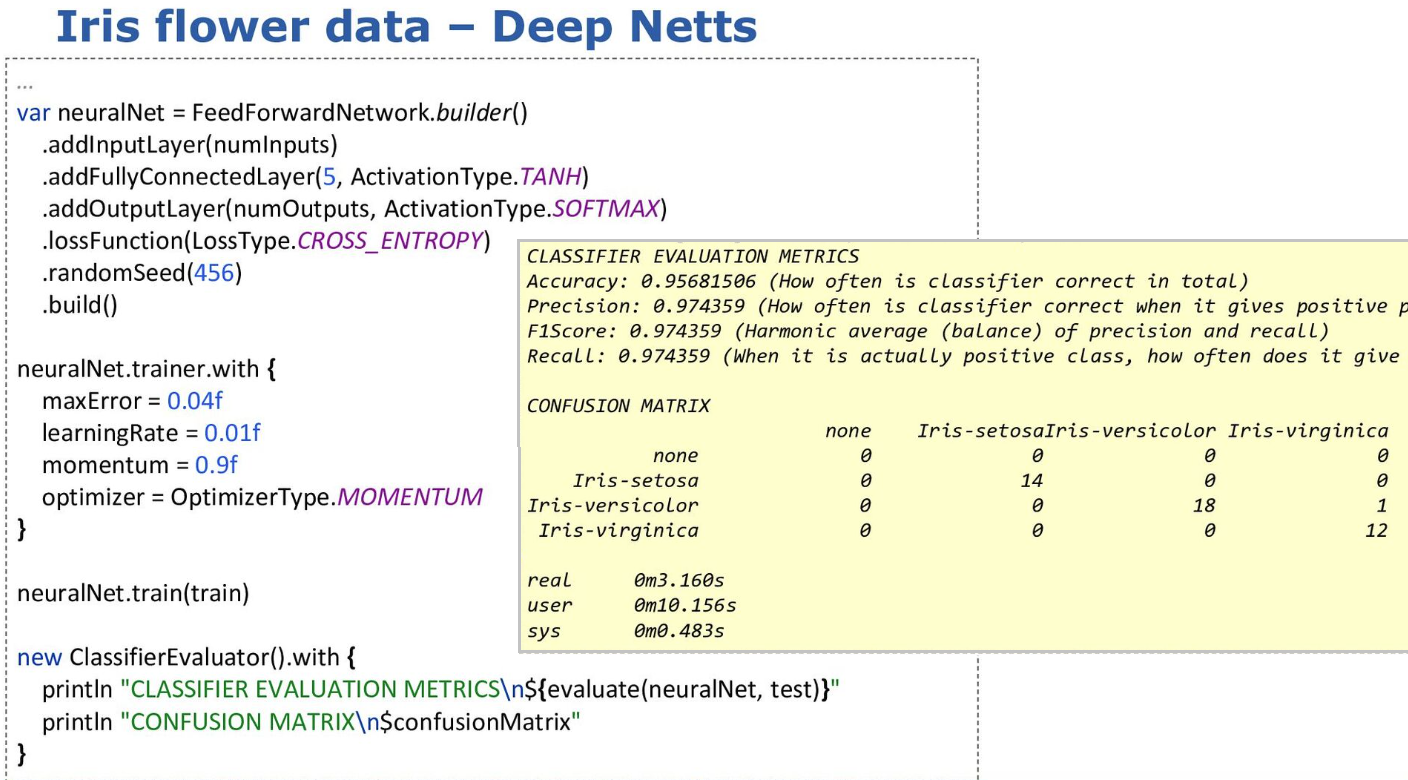
-
Compiling the script using the Groovy compiler with the
--compile-staticswitch and then using GraalVM to build a native image gave a more than 10 times speed increase:
Check out the slide deck for more information.
Getting Started with the Micronaut Framework
Sergio del Amo gave a talk on
Getting Started with the Micronaut Framework, in particular
its support for using Groovy when building microservices.

Highlights:
-
The speed of Micronaut applications comes from its ahead-of-time approach:

-
Micronaut supports a range of runtimes:

-
Micronaut supports a range of messaging technologies:

-
Micronaut supports a range of persistence technologies:

-
Micronaut supports a range of view technologies:

-
You can create Microservices applications using Micronaut launch:
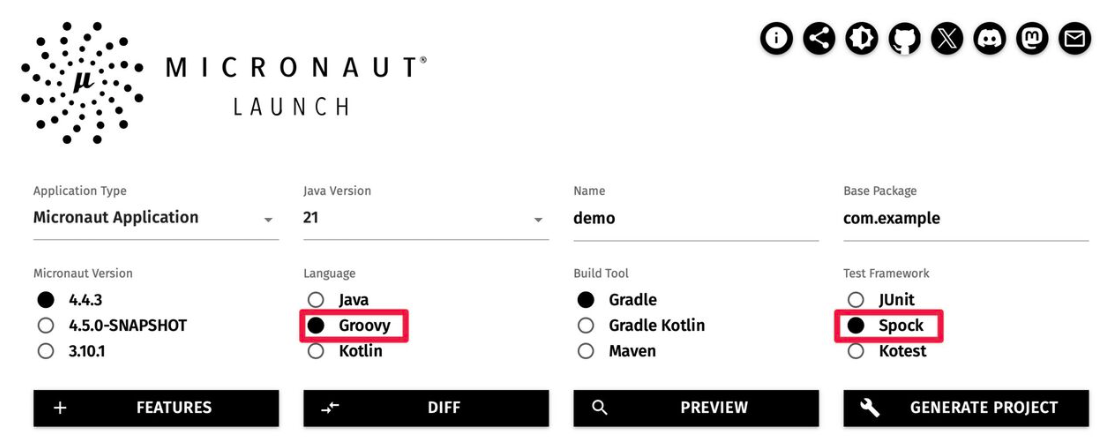
Check out the slide deck for more information.
Whiskey Clustering with Apache Projects:Groovy, Commons CSV, Commons Math, Ignite, Spark, Wayang, Beam, and Flink
This talk looked at the machine language problem of clustering using a well-known whiskey flavor profiles dataset.

Highlights:
-
The case study looked at how to cluster 86 single malt scotch whiskies based on rankings of 12 flavor categories:
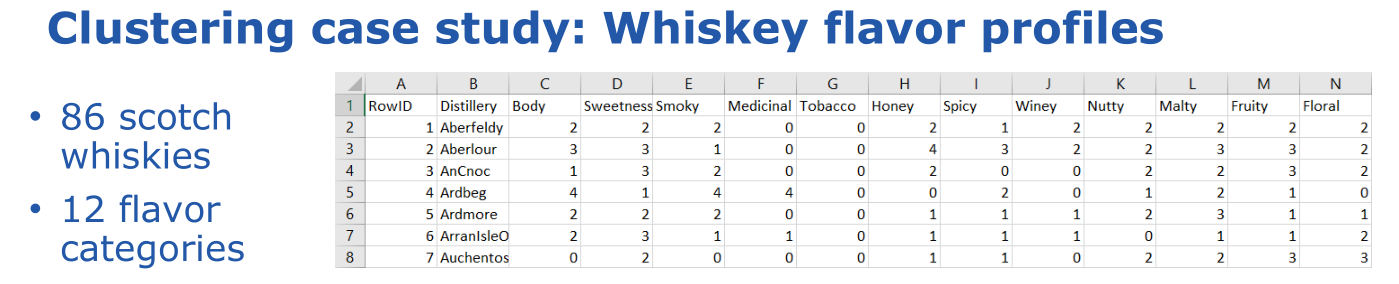
-
There are different algorithms that can be used to do the clustering. K-Means clustering was the key algorithm covered:
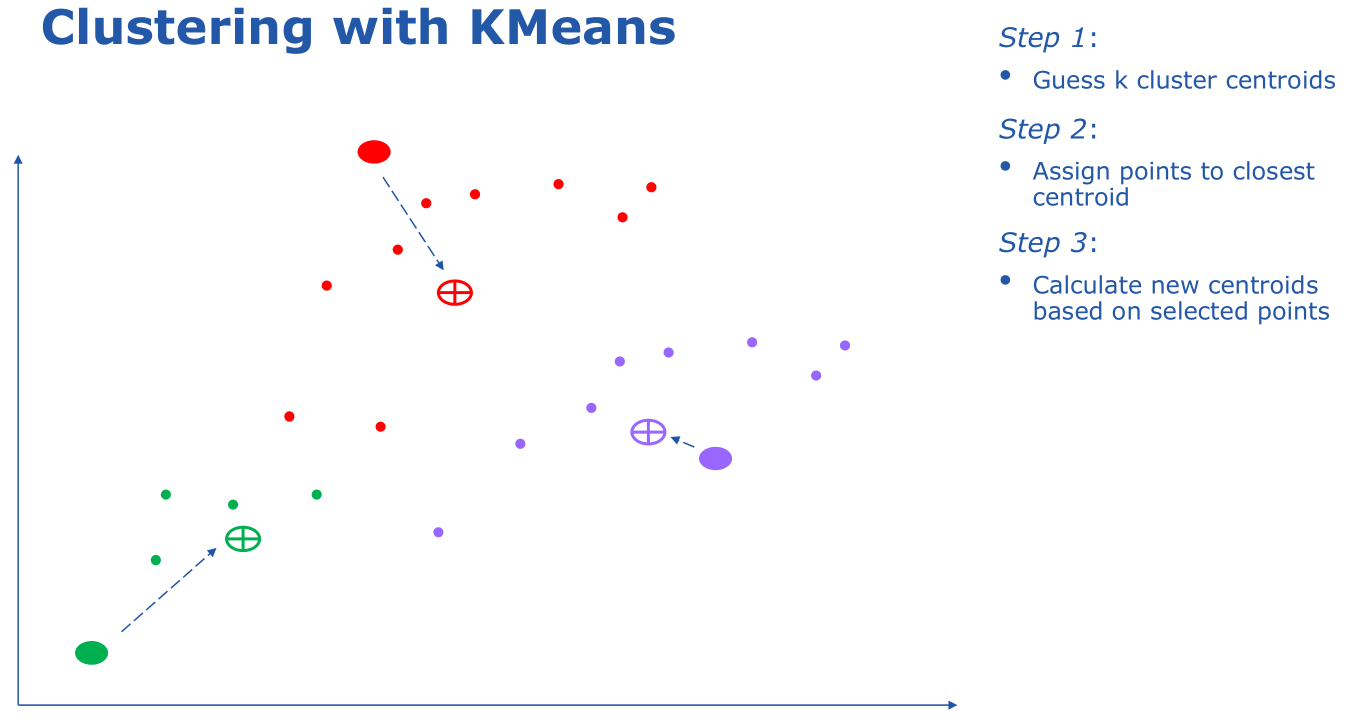
-
The talk covers using vanilla data science libraries including Apache Commons Math to solve this problem, then looks at how you might scale up the problem using a range of Apache technologies. The first technology considered was Apache Ignite. First we read in the data:

-
Then we use Ignite’s distributed clustering libraries to find the centroids:
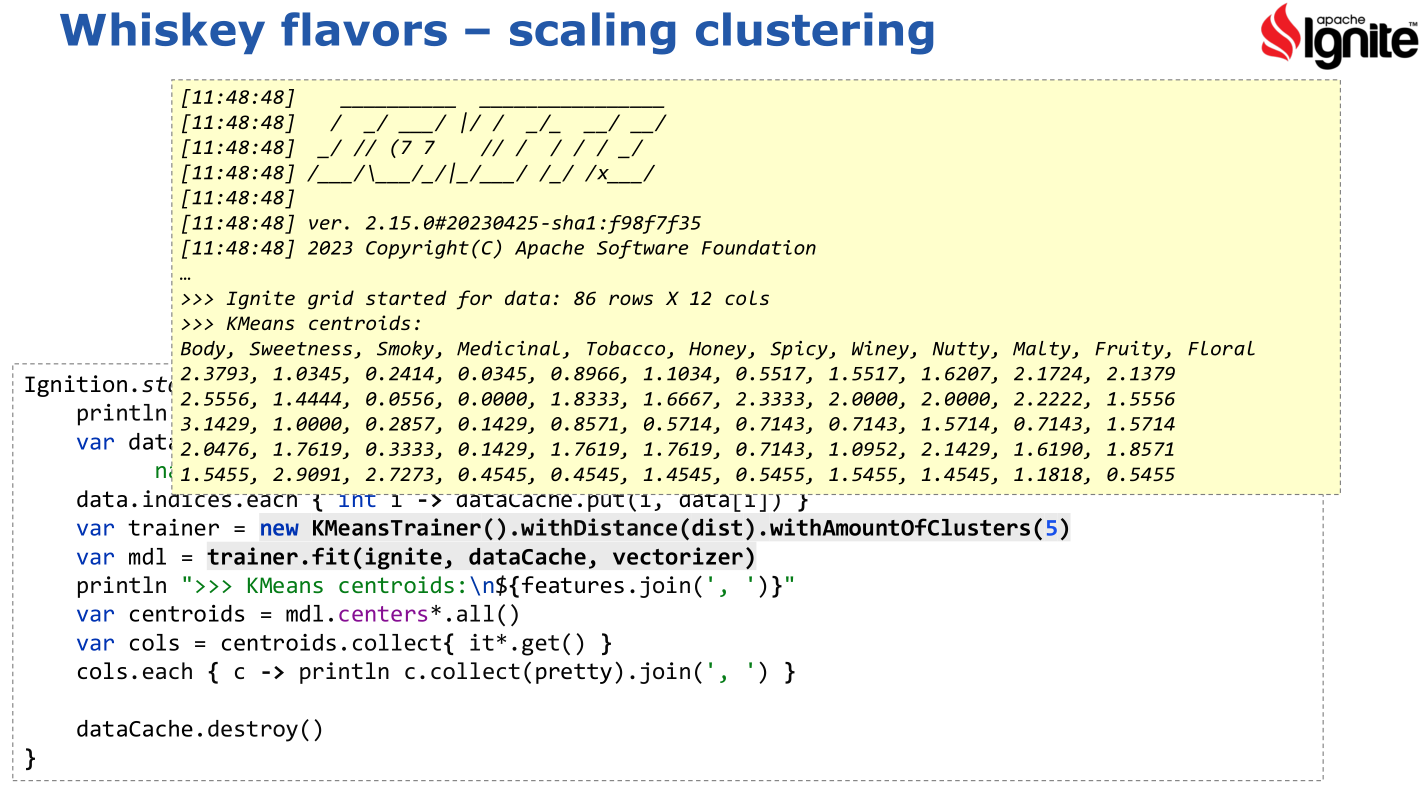
-
Various options to tweak the algorithm and various ways to visualize the results were examined:
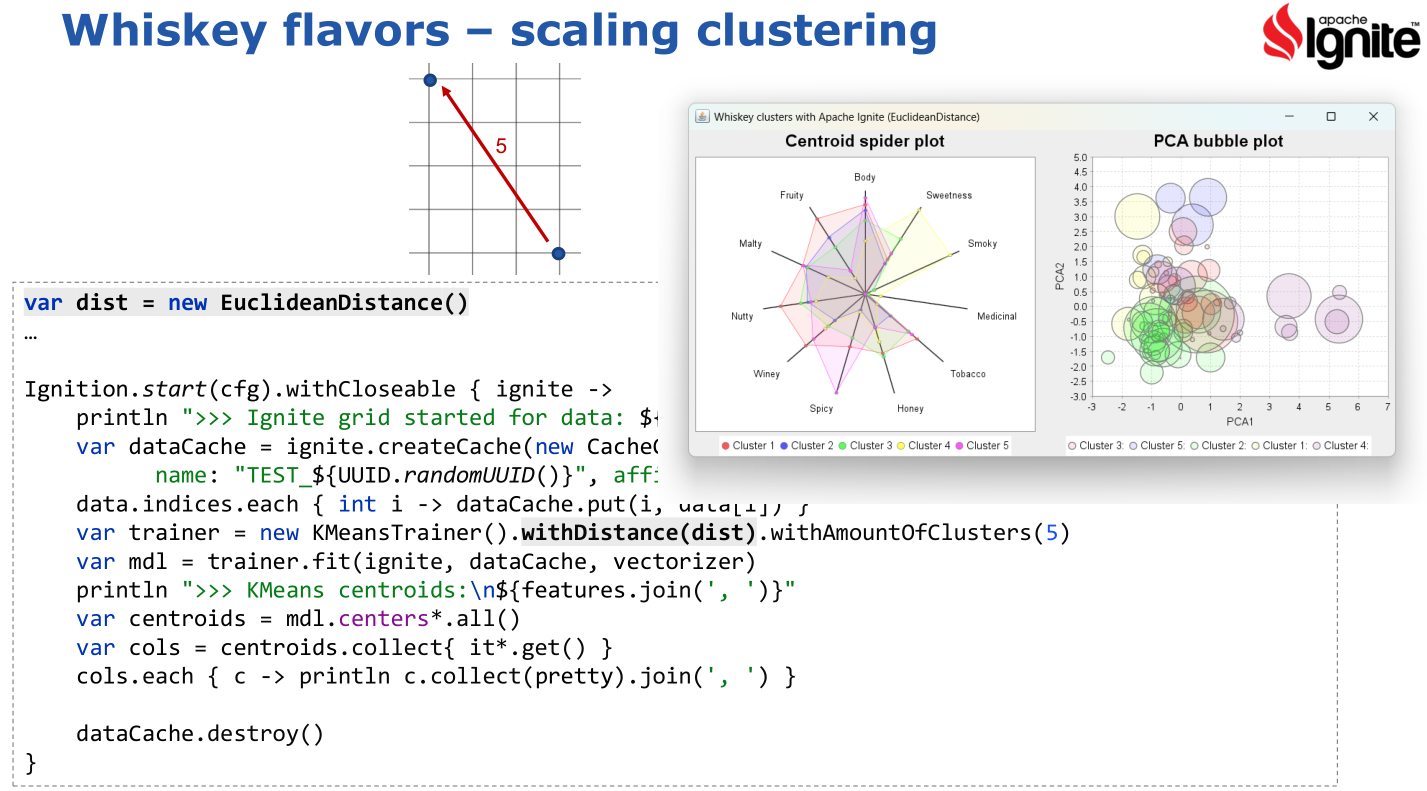
-
The same case study was also done using Spark:
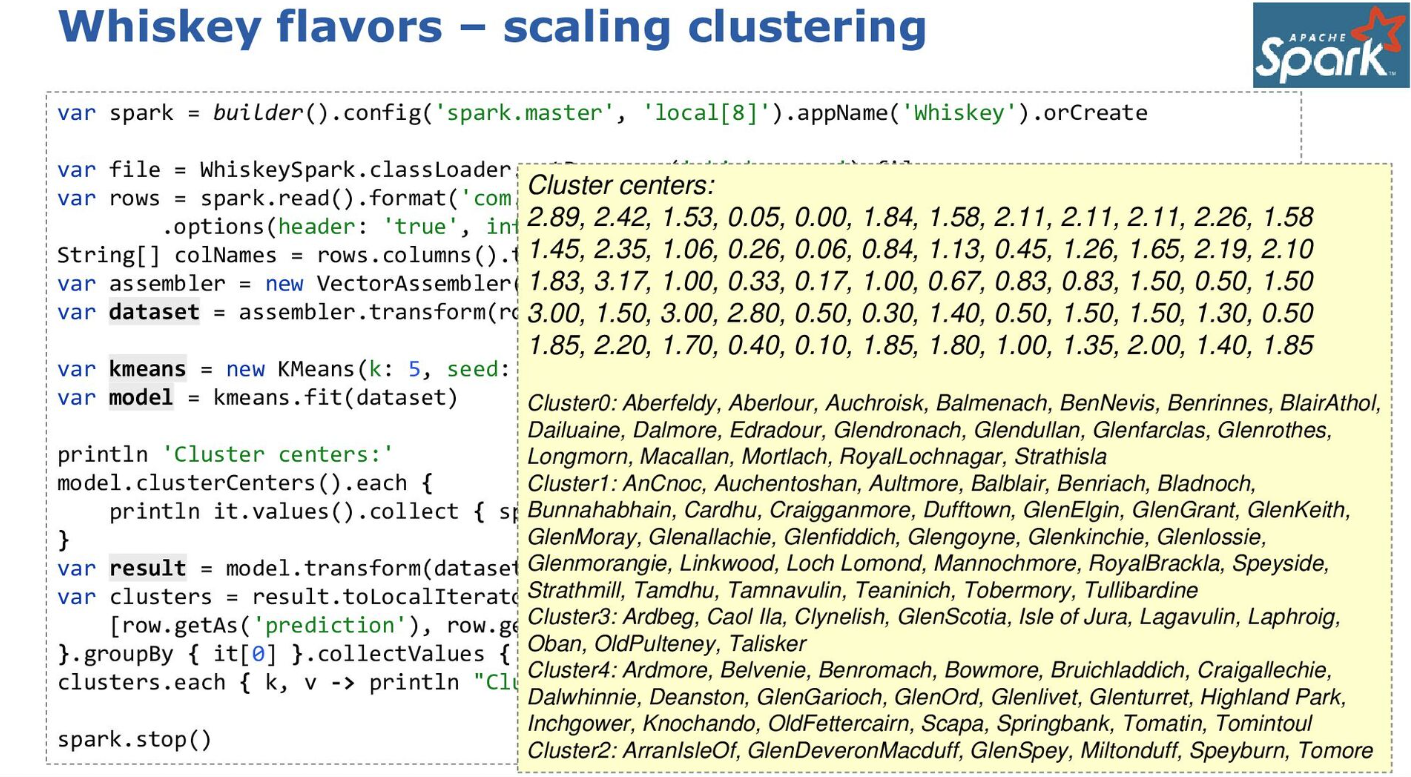
-
The same case study was also done using Apache Wayang:

-
The same case study was also done using Apache Beam (Python-style version shown here):

-
The same case study was also done using Apache Flink:
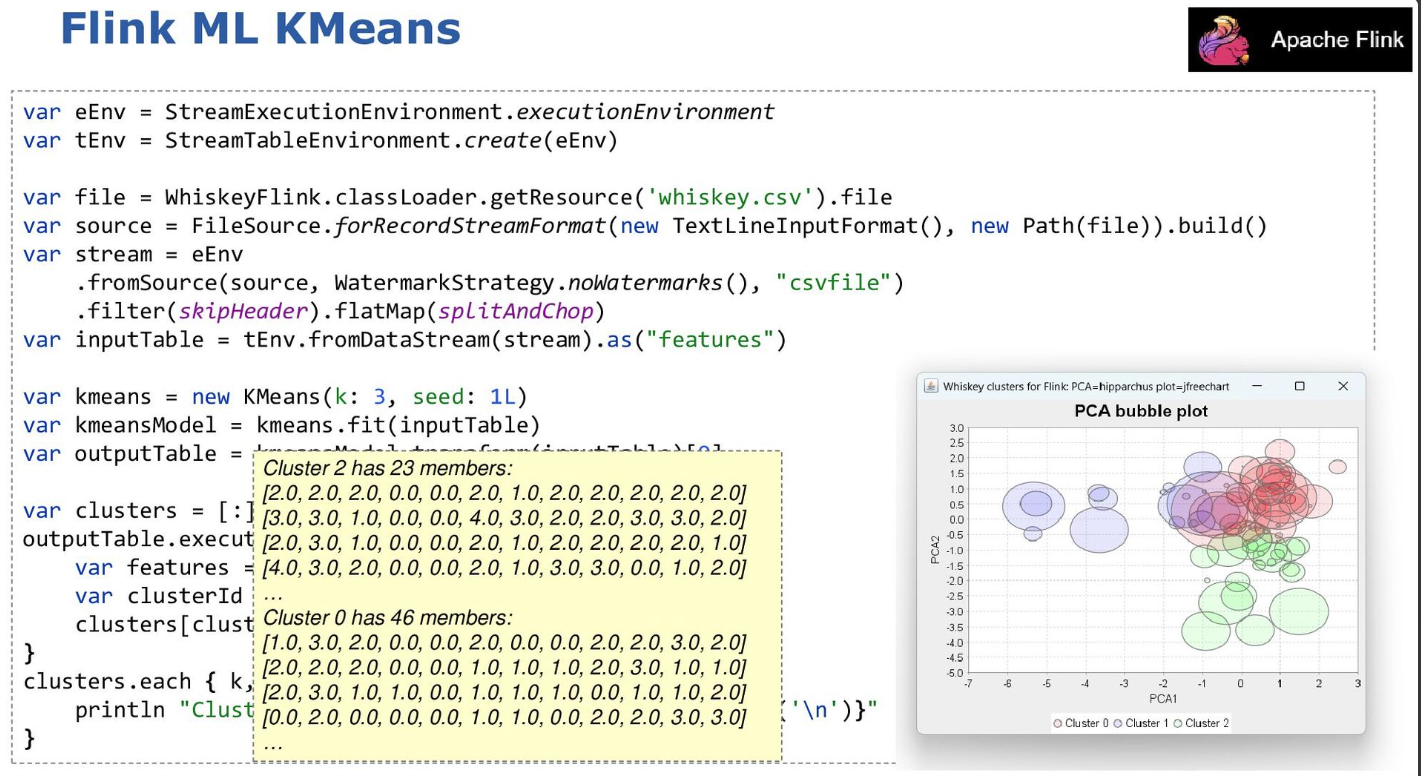
The speakers:

Posters
Community over Code EU also featured a dedicated area for poster sessions. Corridor conversations are a key part of any ASF conference. The posters provided a complimentary way to trigger conversations as well as to learn about a range of topics if the folks who might know all about those topics aren’t in the corridor at the same time as you.


Check out the Groovy poster!
Other information
See also:
-
Additional photos (may be added to over time).
-
The official program includes all tracks and will include links to the slides of the talks if/when available.
Other trip reports:
Upcoming Community Over Code conferences:
-
Hangzhou China, 26-28 July 2024, C Over C Asia 2024
-
Denver Colorado, 7-10 October 2024 C Over C NA 2024.