
Using Graph Databases with Groovy™

Published: 2024-09-02 10:18PM (Last updated: 2026-01-22 02:00PM)
|
Let’s explore graph databases with Apache TinkerPop, Neo4j, Apache AGE, OrientDB, ArcadeDB, Apache HugeGraph, TuGraph, and GraphQL! |
In this blog post, we look at using property graph databases with Groovy. We’ll look at:
-
Some advantages of property graph database technologies
-
Some features of Groovy which make using such databases a little nicer
-
Code examples for a common case study across 7 interesting graph databases
-
Code examples for the same case study using GraphQL
Case Study
The Olympics is over for another 4 years. For sports fans, there were many exciting moments. Let’s look at just one event where the Olympic record was broken several times over the last three years. We’ll look at the women’s 100m backstroke and model the results using graph databases.
Why the women’s 100m backstroke? Well, that was a particularly exciting event in terms of broken records. In Heat 4 of the Tokyo 2021 Olympics, Kylie Masse broke the record previously held by Emily Seebohm from the London 2012 Olympics. A few minutes later in Heat 5, Regan Smith broke the record again. Then in another few minutes in Heat 6, Kaylee McKeown broke the record again. On the following day in Semifinal 1, Regan took back the record. Then, on the following day in the final, Kaylee reclaimed the record. At the Paris 2024 Olympics, Kaylee bettered her own record in the final. Then a few days later, Regan lead off the 4 x 100m medley relay and broke the backstroke record swimming the first leg. That makes 7 times the record was broken across the last 2 games!

We’ll have vertices in our graph database corresponding to the swimmers and the swims.
We’ll use the labels Swimmer and Swim for these vertices. We’ll have relationships
such as swam and supersedes between vertices.
We’ll explore modelling and querying the event
information using several graph database technologies.
The examples in this post can be found on GitHub.
Why graph databases?
RDBMS systems are many times more popular than graph databases, but there are a range of scenarios where graph databases are often used. Which scenarios? Usually, it boils down to relationships. If there are important relationships between data in your system, graph databases might make sense. Typical usage scenarios include fraud detection, knowledge graphs, recommendations engines, social networks, and supply chain management.
This blog post doesn’t aim to convert everyone to use graph databases all the time, but we’ll show you some examples of when it might make sense and let you make up your own mind. Graph databases certainly represent a very useful tool to have in your toolbox should the need arise.
Graph databases are known for more succinct queries and vastly more efficient queries in some scenarios. As a first example, do you prefer this cypher query (it’s from the TuGraph code we’ll see later but other technologies are similar):
MATCH (sr:Swimmer)-[:swam]->(sm:Swim {at: 'Paris 2024'})
RETURN DISTINCT sr.country AS countryOr the equivalent SQL query assuming we were storing the information in relational tables:
SELECT DISTINCT country FROM Swimmer
LEFT JOIN Swimmer_Swim
ON Swimmer.swimmerId = Swimmer_Swim.fkSwimmer
LEFT JOIN Swim
ON Swim.swimId = Swimmer_Swim.fkSwim
WHERE Swim.at = 'Paris 2024'This SQL query is typical of what is required when we have a many-to-many relationship between our entities, in this case swimmers and swims. Many-to-many is required to correctly model relay swims like the last record swim (though for brevity, we haven’t included the other relay swimmers in our dataset). The multiple joins in that query can also be notoriously slow for large datasets.
We’ll see other examples later too, one being a query involving traversal of relationships. Here is the cypher (again from TuGraph):
MATCH (s1:Swim)-[:supersedes*1..10]->(s2:Swim {at: 'London 2012'})
RETURN s1.at as at, s1.event as eventAnd the equivalent SQL:
WITH RECURSIVE traversed(swimId) AS (
SELECT fkNew FROM Supersedes
WHERE fkOld IN (
SELECT swimId FROM Swim
WHERE event = 'Heat 4' AND at = 'London 2012'
)
UNION ALL
SELECT Supersedes.fkNew as swimId
FROM traversed as t
JOIN Supersedes
ON t.swimId = Supersedes.fkOld
WHERE t.swimId = swimId
)
SELECT at, event FROM Swim
WHERE swimId IN (SELECT * FROM traversed)Here we have a Supersedes table and a recursive SQL function, traversed.
The details aren’t important, but it shows the kind of complexity typically
required for the kind of relationship traversal we are looking at.
There are certainly far more complex SQL examples for different kinds of
traversals like shortest path.
This example used TuGraph’s Cypher variant as the Query language. Not all the databases we’ll look at support Cypher, but they all have some kind of query language or API that makes such queries shorter.
Several of the other databases do support a variant of Cypher. Others support different SQL-like query languages. We’ll also see several JMV-based databases which support TinkerPop/Gremlin. It’s a Groovy-based technology and will be our first technology to explore. Recently, ISO published an international standard, GQL, for property graph databases. We expect to see databases supporting that standard in the not too distant future.
Now, it’s time to explore the case study using our different database technologies. We tried to pick technologies that seem reasonably well maintained, had reasonable JVM support, and had any features that seemed worth showing off. Several we selected because they have TinkerPop/Gremlin support.
Apache TinkerPop
Our first technology to examine is Apache TinkerPop™.

TinkerPop is an open source computing framework for graph databases. It provides a common abstraction layer, and a graph query language, called Gremlin. This allows you to work with numerous graph database implementations in a consistent way. TinkerPop also provides its own graph engine implementation, called TinkerGraph, which is what we’ll use initially. TinkerPop/Gremlin will be a technology we revisit for other databases later.
We’ll look at the swims for the medalists and record breakers at the Tokyo 2021 and Paris 2024 Olympics in the women’s 100m backstroke. For reference purposes, we’ll also include the previous swim that set an olympic record.
We’ll start by creating a new in-memory graph database and create a helper object for traversing the graph:
var graph = TinkerGraph.open()
var g = traversal().withEmbedded(graph)Next, let’s create the information relevant for the previous Olympic record which was set at the London 2012 Olympics. Emily Seebohm set that record in Heat 4:
var es = g.addV('Swimmer').property(name: 'Emily Seebohm', country: '🇦🇺').next()
swim1 = g.addV('Swim').property(at: 'London 2012', event: 'Heat 4', time: 58.23, result: 'First').next()
es.addEdge('swam', swim1)We can print out some information from our newly created nodes (vertices) by querying the properties of two nodes respectively:
var (name, country) = ['name', 'country'].collect { es.value(it) }
var (at, event, time) = ['at', 'event', 'time'].collect { swim1.value(it) }
println "$name from $country swam a time of $time in $event at the $at Olympics"Which has this output:
Emily Seebohm from 🇦🇺 swam a time of 58.23 in Heat 4 at the London 2012 Olympics
So far, we’ve just been using the Java API from TinkerPop. It also provides some additional syntactic sugar for Groovy. We can enable the syntactic sugar with:
SugarLoader.load()Which then lets us write (instead of the three earlier lines) the slightly shorter:
println "$es.name from $es.country swam a time of $swim1.time in $swim1.event at the $swim1.at Olympics"This uses Groovy’s normal property access syntax and has the same output when executed.
Let’s create some helper methods to simplify creation of the remaining information.
def insertSwimmer(TraversalSource g, name, country) {
g.addV('Swimmer').property(name: name, country: country).next()
}
def insertSwim(TraversalSource g, at, event, time, result, swimmer) {
var swim = g.addV('Swim').property(at: at, event: event, time: time, result: result).next()
swimmer.addEdge('swam', swim)
swim
}Now we can create the remaining swim information:
var km = insertSwimmer(g, 'Kylie Masse', '🇨🇦')
var swim2 = insertSwim(g, 'Tokyo 2021', 'Heat 4', 58.17, 'First', km)
swim2.addEdge('supersedes', swim1)
var swim3 = insertSwim(g, 'Tokyo 2021', 'Final', 57.72, '🥈', km)
var rs = insertSwimmer(g, 'Regan Smith', '🇺🇸')
var swim4 = insertSwim(g, 'Tokyo 2021', 'Heat 5', 57.96, 'First', rs)
swim4.addEdge('supersedes', swim2)
var swim5 = insertSwim(g, 'Tokyo 2021', 'Semifinal 1', 57.86, '', rs)
var swim6 = insertSwim(g, 'Tokyo 2021', 'Final', 58.05, '🥉', rs)
var swim7 = insertSwim(g, 'Paris 2024', 'Final', 57.66, '🥈', rs)
var swim8 = insertSwim(g, 'Paris 2024', 'Relay leg1', 57.28, 'First', rs)
var kmk = insertSwimmer(g, 'Kaylee McKeown', '🇦🇺')
var swim9 = insertSwim(g, 'Tokyo 2021', 'Heat 6', 57.88, 'First', kmk)
swim9.addEdge('supersedes', swim4)
swim5.addEdge('supersedes', swim9)
var swim10 = insertSwim(g, 'Tokyo 2021', 'Final', 57.47, '🥇', kmk)
swim10.addEdge('supersedes', swim5)
var swim11 = insertSwim(g, 'Paris 2024', 'Final', 57.33, '🥇', kmk)
swim11.addEdge('supersedes', swim10)
swim8.addEdge('supersedes', swim11)
var kb = insertSwimmer(g, 'Katharine Berkoff', '🇺🇸')
var swim12 = insertSwim(g, 'Paris 2024', 'Final', 57.98, '🥉', kb)Note that we just entered the swims where medals were won or where olympic records were broken. We could easily have added more swimmers, other strokes and distances, relay events, and even other sports if we wanted to.
Let’s have a look at what our graph now looks like:
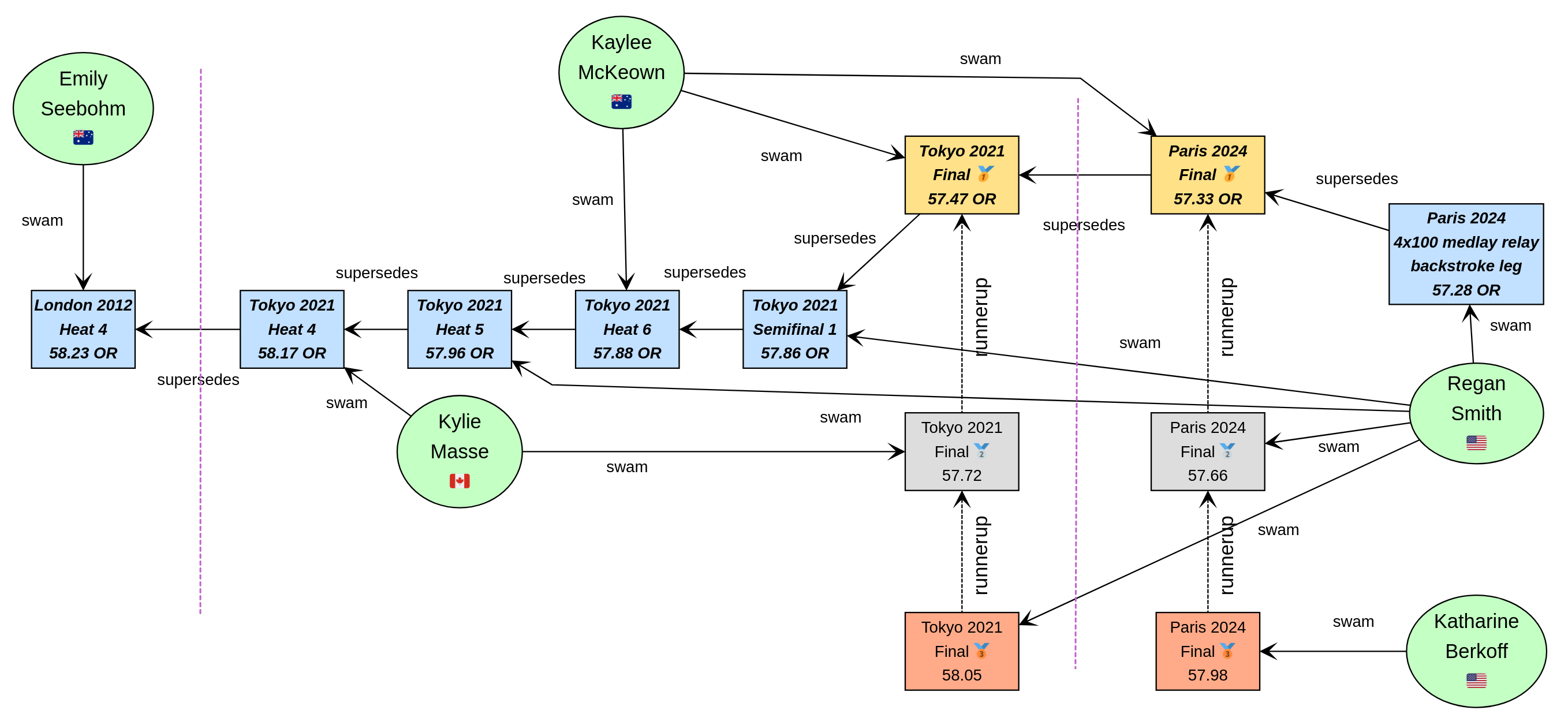
We now might want to query the graph in numerous ways. For instance, what countries had success at the Paris 2024 olympics, where success is defined, for the purposes of this query, as winning a medal or breaking a record. Of course, just having a swimmer make the olympic team is a great success - but let’s keep our example simple for now.
var successInParis = g.V().out('swam').has('at', 'Paris 2024').in()
.values('country').toSet()
assert successInParis == ['🇺🇸', '🇦🇺'] as SetBy way of explanation, we find all nodes with an outgoing swam edge
pointing to a swim that was at the Paris 2024 olympics, i.e.
all the swimmers from Paris 2024. We then find the set of countries
represented. We are using sets here to remove duplicates, and also
we aren’t imposing an ordering on the returned results so we compare
sets on both sides.
Similarly, we can find the olympic records set during heat swims:
var recordSetInHeat = g.V().has('Swim','event', startingWith('Heat')).values('at').toSet()
assert recordSetInHeat == ['London 2012', 'Tokyo 2021'] as SetOr, we can find the times of the records set during finals:
var recordTimesInFinals = g.V().has('event', 'Final').as('ev').out('supersedes')
.select('ev').values('time').toSet()
assert recordTimesInFinals == [57.47, 57.33] as SetMaking use of the Groovy syntactic sugar gives simpler versions:
var successInParis = g.V.out('swam').has('at', 'Paris 2024').in.country.toSet
assert successInParis == ['🇺🇸', '🇦🇺'] as Set
var recordSetInHeat = g.V.has('Swim','event', startingWith('Heat')).at.toSet
assert recordSetInHeat == ['London 2012', 'Tokyo 2021'] as Set
var recordTimesInFinals = g.V.has('event', 'Final').as('ev').out('supersedes').select('ev').time.toSet
assert recordTimesInFinals == [57.47, 57.33] as SetGroovy happens to be very good at allowing you to add syntactic sugar for your own programs or existing classes. TinkerPop’s special Groovy support is just one example of this. Your vendor could certainly supply such a feature for your favorite graph database (why not ask them?) but we’ll look shortly at how you could write such syntactic sugar yourself when we explore Neo4j.
Our examples so far are all interesting,
but graph databases really excel when performing queries
involving multiple edge traversals. Let’s look
at all the olympic records set in 2021 and 2024,
i.e. all records set after London 2012 (swim1 from earlier):
println "Olympic records after ${g.V(swim1).values('at', 'event').toList().join(' ')}: "
println g.V(swim1).repeat(in('supersedes')).as('sw').emit()
.values('at').concat(' ')
.concat(select('sw').values('event')).toList().join('\n')Or after using the Groovy syntactic sugar, the query becomes:
println g.V(swim1).repeat(in('supersedes')).as('sw').emit
.at.concat(' ').concat(select('sw').event).toList.join('\n')Both have this output:
Olympic records after London 2012 Heat 4: Tokyo 2021 Heat 4 Tokyo 2021 Heat 5 Tokyo 2021 Heat 6 Tokyo 2021 Semifinal 1 Tokyo 2021 Final Paris 2024 Final Paris 2024 Relay leg1
|
Note
|
While not important for our examples, TinkerPop has a GraphMLWriter class which can write out our
graph in GraphML, which is how the earlier image of Graphs and Nodes was initially generated.
|
Neo4j
Our next technology to examine is neo4j. Neo4j is a graph database storing nodes and edges. Nodes and edges may have a label and properties (or attributes).

Neo4j models edge relationships using enums. Let’s create an enum for our example:
enum SwimmingRelationships implements RelationshipType {
swam, supersedes, runnerup
}We’ll use Neo4j in embedded mode and perform all of our operations as part of a transaction:
// ... set up managementService ...
var graphDb = managementService.database(DEFAULT_DATABASE_NAME)
try (Transaction tx = graphDb.beginTx()) {
// ... other Neo4j code below here ...
}Let’s create our nodes and edges using Neo4j. First the existing Olympic record:
es = tx.createNode(label('Swimmer'))
es.setProperty('name', 'Emily Seebohm')
es.setProperty('country', '🇦🇺')
swim1 = tx.createNode(label('Swim'))
swim1.setProperty('event', 'Heat 4')
swim1.setProperty('at', 'London 2012')
swim1.setProperty('result', 'First')
swim1.setProperty('time', 58.23d)
es.createRelationshipTo(swim1, swam)
var name = es.getProperty('name')
var country = es.getProperty('country')
var at = swim1.getProperty('at')
var event = swim1.getProperty('event')
var time = swim1.getProperty('time')
println "$name from $country swam a time of $time in $event at the $at Olympics"While there is nothing wrong with this code, Groovy has many features for making code more succinct. Let’s use some dynamic metaprogramming to achieve just that.
Node.metaClass {
propertyMissing { String name, val -> delegate.setProperty(name, val) }
propertyMissing { String name -> delegate.getProperty(name) }
methodMissing { String name, args ->
delegate.createRelationshipTo(args[0], SwimmingRelationships."$name")
}
}What does this do? The propertyMissing lines catch attempts to use Groovy’s
normal property access and funnels then through appropriate getProperty and setProperty methods.
The methodMissing line means any attempted method calls that we don’t recognize
are intended to be relationship creation, so we funnel them through the appropriate
createRelationshipTo method call.
Now we can use normal Groovy property access for setting the node properties. It looks much cleaner. We define an edge relationship simply by calling a method having the relationship name.
km = tx.createNode(label('Swimmer'))
km.name = 'Kylie Masse'
km.country = '🇨🇦'The code is already a little cleaner, but we can tweak the metaprogramming a little
more to get rid of the noise associated with the label method:
Transaction.metaClass {
createNode { String labelName -> delegate.createNode(label(labelName)) }
}This adds an overload for createNode that takes a String, and
node creation is improved again, as we can see here:
swim2 = tx.createNode('Swim')
swim2.time = 58.17d
swim2.result = 'First'
swim2.event = 'Heat 4'
swim2.at = 'Tokyo 2021'
km.swam(swim2)
swim2.supersedes(swim1)
swim3 = tx.createNode('Swim')
swim3.time = 57.72d
swim3.result = '🥈'
swim3.event = 'Final'
swim3.at = 'Tokyo 2021'
km.swam(swim3)The code for relationships is certainly a lot cleaner too, and it was quite a minimal amount of work to define the necessary metaprogramming.
With a little bit more work, we could use static metaprogramming techniques. This would give us better IDE completion. We’ll have more to say about improved type checking at the end of this post. For now though, let’s continue with defining the rest of our graph.
We can redefine our insertSwimmer and insertSwim methods using Neo4j implementation
calls, and then our earlier code could be used to create our graph. Now let’s
investigate what the queries look like. We’ll start with querying via
the API. and later look at using Cypher.
First, the successful countries in Paris 2024:
var swimmers = [es, km, rs, kmk, kb]
var successInParis = swimmers.findAll { swimmer ->
swimmer.getRelationships(swam).any { run ->
run.getOtherNode(swimmer).at == 'Paris 2024'
}
}
assert successInParis*.country.unique() == ['🇺🇸', '🇦🇺']Then, at which olympics were records broken in heats:
var swims = [swim1, swim2, swim3, swim4, swim5, swim6, swim7, swim8, swim9, swim10, swim11, swim12]
var recordSetInHeat = swims.findAll { swim ->
swim.event.startsWith('Heat')
}*.at
assert recordSetInHeat.unique() == ['London 2012', 'Tokyo 2021']Now, what were the times for records broken in finals:
var recordTimesInFinals = swims.findAll { swim ->
swim.event == 'Final' && swim.hasRelationship(supersedes)
}*.time
assert recordTimesInFinals == [57.47d, 57.33d]To see traversal in action, Neo4j has a special API for doing such queries:
var info = { s -> "$s.at $s.event" }
println "Olympic records following ${info(swim1)}:"
for (Path p in tx.traversalDescription()
.breadthFirst()
.relationships(supersedes)
.evaluator(Evaluators.fromDepth(1))
.uniqueness(Uniqueness.NONE)
.traverse(swim1)) {
println p.endNode().with(info)
}Earlier versions of Neo4j also supported Gremlin, so we could have written our queries in the same was as we did for TinkerPop. That technology is deprecated in recent Neo4j versions, and instead they now offer a Cypher query language. We can use that language for all of our previous queries as shown here:
assert tx.execute('''
MATCH (s:Swim WHERE s.event STARTS WITH 'Heat')
WITH s.at as at
WITH DISTINCT at
RETURN at
''')*.at == ['London 2012', 'Tokyo 2021']
assert tx.execute('''
MATCH (s1:Swim {event: 'Final'})-[:supersedes]->(s2:Swim)
RETURN s1.time AS time
''')*.time == [57.47d, 57.33d]
tx.execute('''
MATCH (s1:Swim)-[:supersedes]->{1,}(s2:Swim { at: $at })
RETURN s1
''', [at: swim1.at])*.s1.each { s ->
println "$s.at $s.event"
}This blog post is definitely, not meant to be an advanced course on graph database design, but it is worth noting a few points.
Deciding which information should be stored as node properties and which as relationships
still requires developer judgement. For example, we could have added a Boolean olympicRecord
property to our Swim nodes. Certain queries might now become simpler, or at least more familiar
to traditional RDBMS SQL developers, but other queries might become much harder to write
and potentially much less efficient.
This is the kind of thing which needs to be thought through and sometimes experimented with.
Suppose, in the case where a record is broken, we wanted to see which other swimmers (in our case medallists in the final) also broke the previous record. We could write a query to find this as follows:
assert tx.execute('''
MATCH (sr1:Swimmer)-[:swam]->(sm1:Swim {event: 'Final'}), (sm2:Swim {event: 'Final'})-[:supersedes]->(sm3:Swim)
WHERE sm1.at = sm2.at AND sm1 <> sm2 AND sm1.time < sm3.time
RETURN sr1.name as name
''')*.name == ['Kylie Masse']It’s not too bad, but if we had a much larger graph of data, it could be quite slow.
We could instead opt to use an additional relationship, called runnerup in our graph.
swim6.runnerup(swim3)
swim3.runnerup(swim10)
swim12.runnerup(swim7)
swim7.runnerup(swim11)The visualization is something like this:
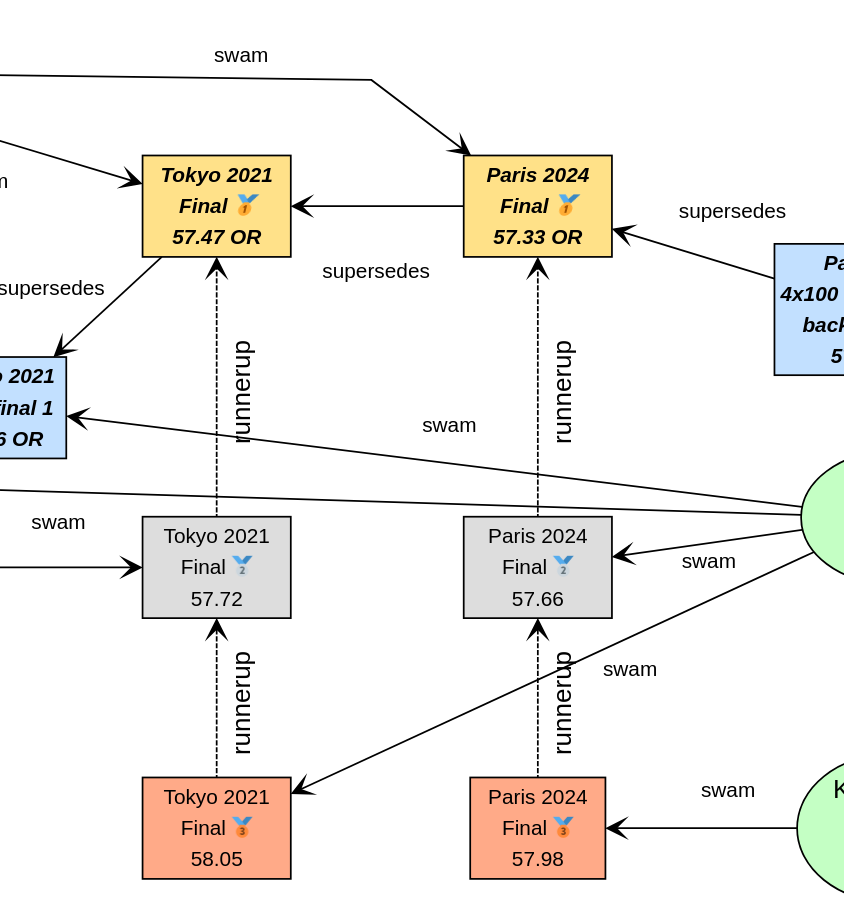
It essentially makes it easier to find the other medalists if we know any one of them.
The resulting query becomes this:
assert tx.execute('''
MATCH (sr1:Swimmer)-[:swam]->(sm1:Swim {event: 'Final'})-[:runnerup]->{1,2}(sm2:Swim {event: 'Final'})-[:supersedes]->(sm3:Swim)
WHERE sm1.time < sm3.time
RETURN sr1.name as name
''')*.name == ['Kylie Masse']The MATCH clause is similar in complexity, the WHERE clause is much simpler. The query is probably faster too, but it is a tradeoff that should be weighed up.
Apache AGE
The next technology we’ll look at is the Apache AGE™ graph database. Apache AGE leverages PostgreSQL for storage.
![]()
![]()
We installed Apache AGE via a Docker Image as outlined in the Apache AGE manual.
Since Apache AGE offers a SQL-inspired graph database experience, we use Groovy’s SQL facilities to interact with the database:
Sql.withInstance(DB_URL, USER, PASS, 'org.postgresql.jdbc.PgConnection') { sql ->
// enable Apache AGE extension, then use Sql connection ...
}For creating our nodes and subsequent querying, we use SQL statements with embedded cypher clauses. Here is the statement for creating out nodes and edges:
sql.execute'''
SELECT * FROM cypher('swimming_graph', $$ CREATE
(es:Swimmer {name: 'Emily Seebohm', country: '🇦🇺'}),
(swim1:Swim {event: 'Heat 4', result: 'First', time: 58.23, at: 'London 2012'}),
(es)-[:swam]->(swim1),
(km:Swimmer {name: 'Kylie Masse', country: '🇨🇦'}),
(swim2:Swim {event: 'Heat 4', result: 'First', time: 58.17, at: 'Tokyo 2021'}),
(km)-[:swam]->(swim2),
(swim2)-[:supersedes]->(swim1),
(swim3:Swim {event: 'Final', result: '🥈', time: 57.72, at: 'Tokyo 2021'}),
(km)-[:swam]->(swim3),
(rs:Swimmer {name: 'Regan Smith', country: '🇺🇸'}),
(swim4:Swim {event: 'Heat 5', result: 'First', time: 57.96, at: 'Tokyo 2021'}),
(rs)-[:swam]->(swim4),
(swim4)-[:supersedes]->(swim2),
(swim5:Swim {event: 'Semifinal 1', result: 'First', time: 57.86, at: 'Tokyo 2021'}),
(rs)-[:swam]->(swim5),
(swim6:Swim {event: 'Final', result: '🥉', time: 58.05, at: 'Tokyo 2021'}),
(rs)-[:swam]->(swim6),
(swim7:Swim {event: 'Final', result: '🥈', time: 57.66, at: 'Paris 2024'}),
(rs)-[:swam]->(swim7),
(swim8:Swim {event: 'Relay leg1', result: 'First', time: 57.28, at: 'Paris 2024'}),
(rs)-[:swam]->(swim8),
(kmk:Swimmer {name: 'Kaylee McKeown', country: '🇦🇺'}),
(swim9:Swim {event: 'Heat 6', result: 'First', time: 57.88, at: 'Tokyo 2021'}),
(kmk)-[:swam]->(swim9),
(swim9)-[:supersedes]->(swim4),
(swim5)-[:supersedes]->(swim9),
(swim10:Swim {event: 'Final', result: '🥇', time: 57.47, at: 'Tokyo 2021'}),
(kmk)-[:swam]->(swim10),
(swim10)-[:supersedes]->(swim5),
(swim11:Swim {event: 'Final', result: '🥇', time: 57.33, at: 'Paris 2024'}),
(kmk)-[:swam]->(swim11),
(swim11)-[:supersedes]->(swim10),
(swim8)-[:supersedes]->(swim11),
(kb:Swimmer {name: 'Katharine Berkoff', country: '🇺🇸'}),
(swim12:Swim {event: 'Final', result: '🥉', time: 57.98, at: 'Paris 2024'}),
(kb)-[:swam]->(swim12)
$$) AS (a agtype)
'''To find which olympics where records were set in heats, we can use the following cypher query:
assert sql.rows('''
SELECT * from cypher('swimming_graph', $$
MATCH (s:Swim)
WHERE left(s.event, 4) = 'Heat'
RETURN s
$$) AS (a agtype)
''').a*.map*.get('properties')*.at.toUnique() == ['London 2012', 'Tokyo 2021']The results come back in a special JSON-like data type called agtype.
From that, we can query the properties and return the at property.
We select the unique ones to remove duplicates.
Similarly, we can find the times of olympic records set in finals as follows:
assert sql.rows('''
SELECT * from cypher('swimming_graph', $$
MATCH (s1:Swim {event: 'Final'})-[:supersedes]->(s2:Swim)
RETURN s1
$$) AS (a agtype)
''').a*.map*.get('properties')*.time == [57.47, 57.33]To print all the olympic records set across Tokyo 2021 and Paris 2024,
we can use eachRow and the following query:
sql.eachRow('''
SELECT * from cypher('swimming_graph', $$
MATCH (s1:Swim)-[:supersedes]->(swim1)
RETURN s1
$$) AS (a agtype)
''') {
println it.a*.map*.get('properties')[0].with{ "$it.at $it.event" }
}The output looks like this:
Tokyo 2021 Heat 4 Tokyo 2021 Heat 5 Tokyo 2021 Heat 6 Tokyo 2021 Final Tokyo 2021 Semifinal 1 Paris 2024 Final Paris 2024 Relay leg1
The Apache AGE project also maintains a viewer tool offering a web-based user interface for visualization of graph data stored in our database. Instructions for installation are available on the GitHub site. The tool allows visualization of the results from any query. For our database, a query returning all nodes and edges creates a visualization like below (we chose to manually re-arrange the nodes):
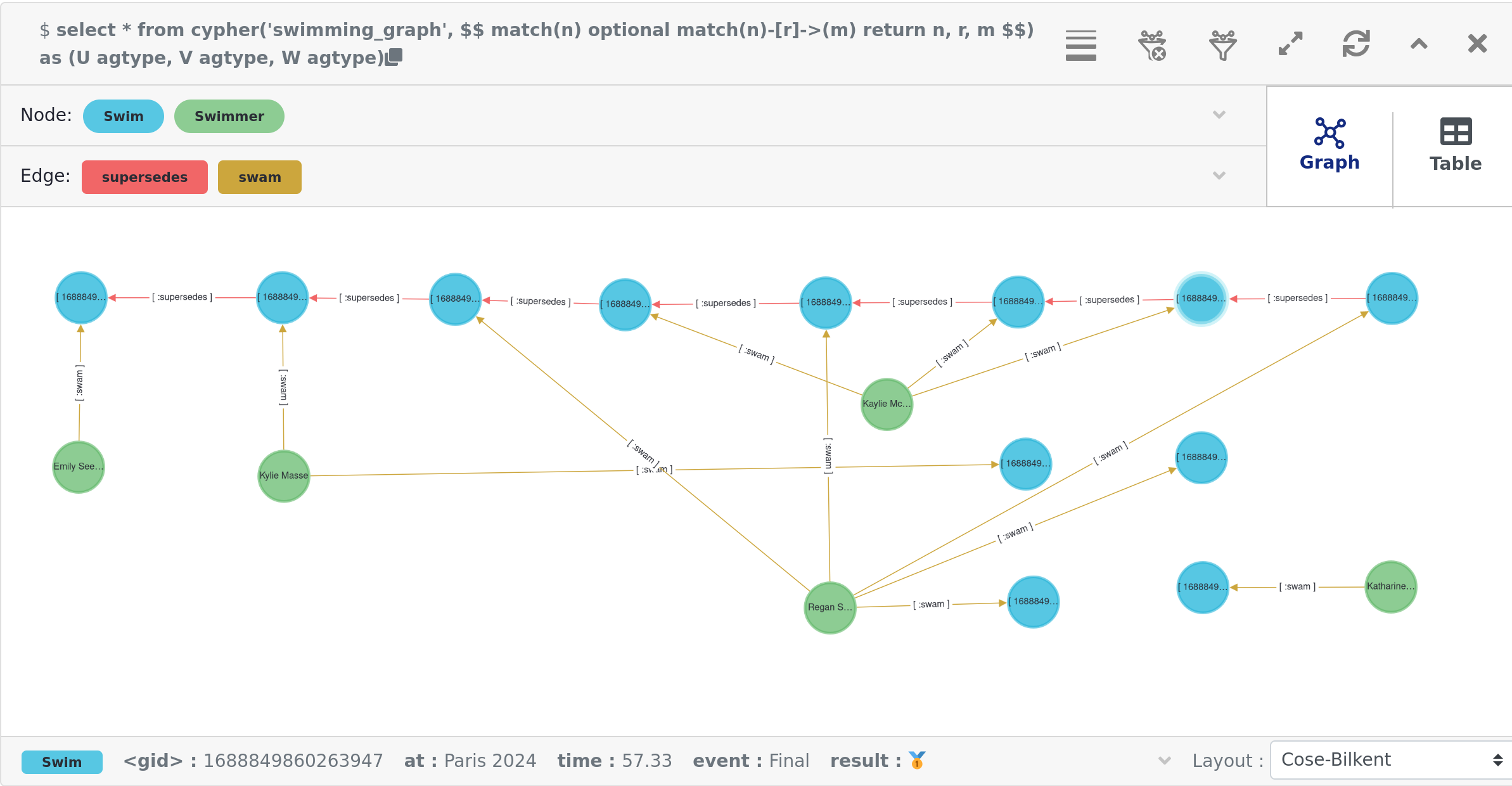
OrientDB
![]()
The next graph database we’ll look at is OrientDB. We used the open source Community edition. We used it in embedded mode but there are instructions for running a docker image as well.
The main claim to fame for OrientDB (and the closely related ArcadeDB we’ll cover next) is that they are multi-model databases, supporting graphs and documents in the one database.
Creating our database and setting up our vertex and edge classes (think mini-schema) is done as follows:
try (var db = context.open("swimming", "admin", "adminpwd")) {
db.createVertexClass('Swimmer')
db.createVertexClass('Swim')
db.createEdgeClass('swam')
db.createEdgeClass('supersedes')
// other code here
}See the GitHub repo for further details.
With initialization out fo the way, we can start defining our nodes and edges:
var es = db.newVertex('Swimmer')
es.setProperty('name', 'Emily Seebohm')
es.setProperty('country', '🇦🇺')
var swim1 = db.newVertex('Swim')
swim1.setProperty('at', 'London 2012')
swim1.setProperty('result', 'First')
swim1.setProperty('event', 'Heat 4')
swim1.setProperty('time', 58.23)
es.addEdge(swim1, 'swam')We can print out the details as before:
var (name, country) = ['name', 'country'].collect { es.getProperty(it) }
var (at, event, time) = ['at', 'event', 'time'].collect { swim1.getProperty(it) }
println "$name from $country swam a time of $time in $event at the $at Olympics"At this point, we could apply some Groovy metaprogramming to make the code more succinct,
but we’ll just flesh out our insertSwimmer and insertSwim helper methods like before.
We can use these to enter the remaining swim information.
Queries are performed using the Multi-Model API using SQL-like queries. Our three queries we’ve seen earlier look like this:
var results = db.query("SELECT expand(out('supersedes').in('supersedes')) FROM Swim WHERE event = 'Final'")
assert results*.getProperty('time').toSet() == [57.47, 57.33] as Set
results = db.query("SELECT expand(out('supersedes')) FROM Swim WHERE event.left(4) = 'Heat'")
assert results*.getProperty('at').toSet() == ['Tokyo 2021', 'London 2012'] as Set
results = db.query("SELECT country FROM ( SELECT expand(in('swam')) FROM Swim WHERE at = 'Paris 2024' )")
assert results*.getProperty('country').toSet() == ['🇺🇸', '🇦🇺'] as SetTraversal looks like this:
results = db.query("TRAVERSE in('supersedes') FROM :swim", swim1)
results.each {
if (it.toElement() != swim1) {
println "${it.getProperty('at')} ${it.getProperty('event')}"
}
}OrientDB also supports Gremlin and a studio Web-UI. Both of these features are very similar to the ArcadeDB counterparts. We’ll examine them next when we look at ArcadeDB.
ArcadeDB
Now, we’ll examine ArcadeDB.
![]()
ArcadeDB is a rewrite/partial fork of OrientDB and carries over its Multi-Model nature. We used it in embedded mode but there are instructions for running a docker image if you prefer.
Not surprisingly, some usage of ArcadeDB is very similar to OrientDB. Initialization changes slightly:
var factory = new DatabaseFactory("swimming")
try (var db = factory.create()) {
db.transaction { ->
db.schema.with {
createVertexType('Swimmer')
createVertexType('Swim')
createEdgeType('swam')
createEdgeType('supersedes')
}
// ... other code goes here ...
}
}Defining the existing record information is done as follows:
var es = db.newVertex('Swimmer')
es.set(name: 'Emily Seebohm', country: '🇦🇺').save()
var swim1 = db.newVertex('Swim')
swim1.set(at: 'London 2012', result: 'First', event: 'Heat 4', time: 58.23).save()
swim1.newEdge('swam', es, false).save()Accessing the information can be done like this:
var (name, country) = ['name', 'country'].collect { es.get(it) }
var (at, event, time) = ['at', 'event', 'time'].collect { swim1.get(it) }
println "$name from $country swam a time of $time in $event at the $at Olympics"ArcadeDB supports multiple query languages. The SQL-like language mirrors the OrientDB offering. Here are our three now familiar queries:
var results = db.query('SQL', '''
SELECT expand(outV()) FROM (SELECT expand(outE('supersedes')) FROM Swim WHERE event = 'Final')
''')
assert results*.toMap().time.toSet() == [57.47, 57.33] as Set
results = db.query('SQL', "SELECT expand(outV()) FROM (SELECT expand(outE('supersedes')) FROM Swim WHERE event.left(4) = 'Heat')")
assert results*.toMap().at.toSet() == ['Tokyo 2021', 'London 2012'] as Set
results = db.query('SQL', "SELECT country FROM ( SELECT expand(out('swam')) FROM Swim WHERE at = 'Paris 2024' )")
assert results*.toMap().country.toSet() == ['🇺🇸', '🇦🇺'] as SetHere is our traversal example:
results = db.query('SQL', "TRAVERSE out('supersedes') FROM :swim", swim1)
results.each {
if (it.toElement() != swim1) {
var props = it.toMap()
println "$props.at $props.event"
}
}ArcadeDB also supports Cypher queries (like Neo4j). The times for records in finals query using the Cypher dialect looks like this:
results = db.query('cypher', '''
MATCH (s1:Swim {event: 'Final'})-[:supersedes]->(s2:Swim)
RETURN s1.time AS time
''')
assert results*.toMap().time.toSet() == [57.47, 57.33] as SetArcadeDB also supports Gremlin queries. The times for records in finals query using the Gremlin dialect looks like this:
results = db.query('gremlin', '''
g.V().has('event', 'Final').as('ev').out('supersedes').select('ev').values('time')
''')
assert results*.toMap().result.toSet() == [57.47, 57.33] as SetRather than just passing a Gremlin query as a String, we can get full access to the TinkerPop environment as this example show:
try (final ArcadeGraph graph = ArcadeGraph.open("swimming")) {
var recordTimesInFinals = graph.traversal().V().has('event', 'Final').as('ev').out('supersedes')
.select('ev').values('time').toSet()
assert recordTimesInFinals == [57.47, 57.33] as Set
}ArcadeDB also supports a Studio Web-UI. Here is an example of using Studio with a query that looks at all nodes and edges associated with the Tokyo 2021 olympics:
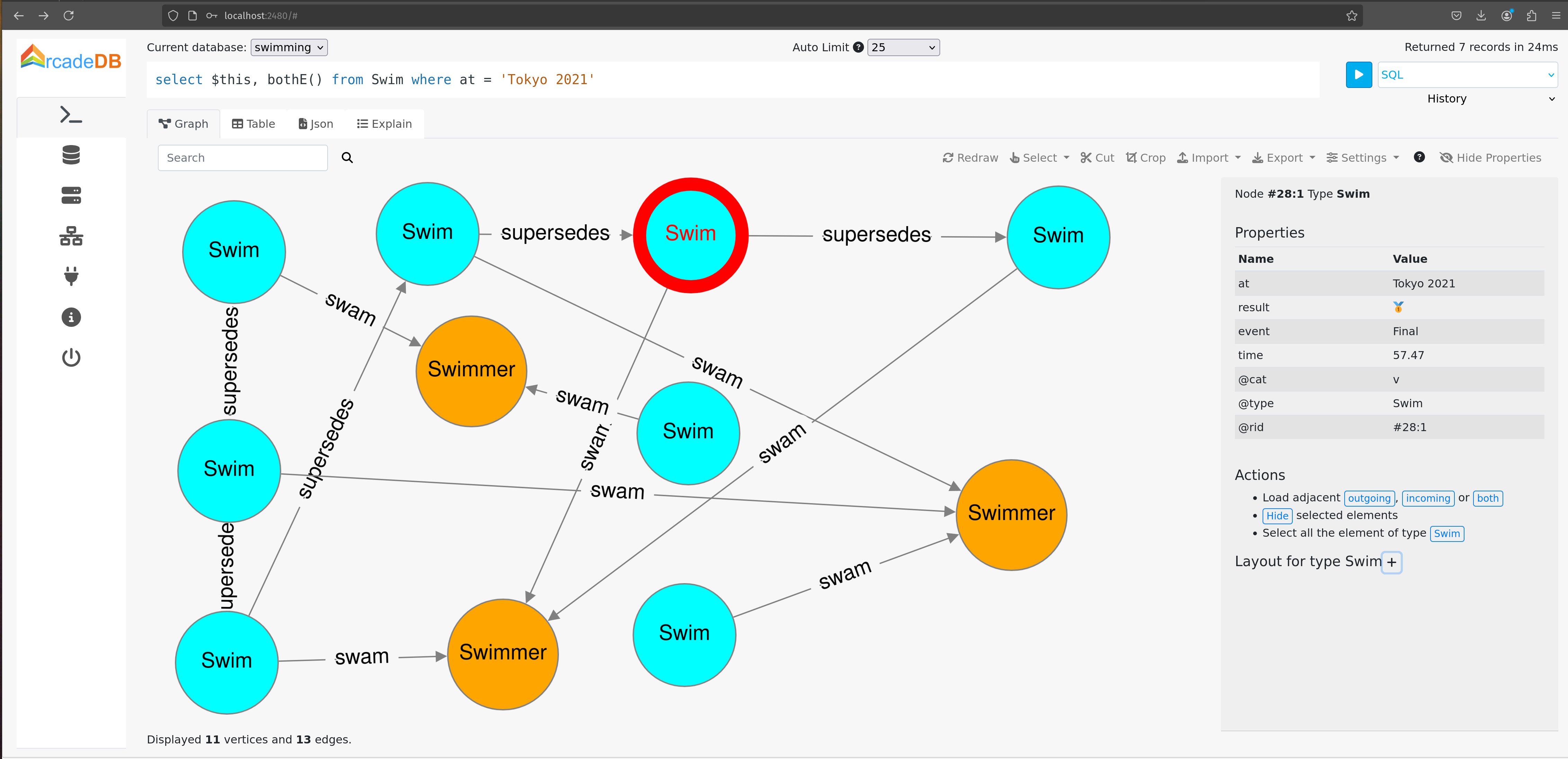
TuGraph
Next, we’ll look at TuGraph.

We used the Community Edition using a docker image as outlined in the documentation and here. TuGraph’s claim to fame is high performance. Certainly, that isn’t really needed for this example, but let’s have a play anyway.
There are a few ways to talk to TuGraph. We’ll use the recommended Neo4j Bolt client which uses the Bolt protocol to talk to the TuGraph server.
We’ll create a session using that client plus a helper run method to invoke our queries.
var authToken = AuthTokens.basic("admin", "73@TuGraph")
var driver = GraphDatabase.driver("bolt://localhost:7687", authToken)
var session = driver.session(SessionConfig.forDatabase("default"))
var run = { String s -> session.run(s) }Next, we set up our database including providing a schema for our nodes, edges and properties.
One point of difference with earlier examples is that TuGraph needs a primary key for each vertex.
Hence, we added the id for our Swim vertex.
'''
CALL db.dropDB()
CALL db.createVertexLabel('Swimmer', 'name', 'name', 'STRING', false, 'country', 'STRING', false)
CALL db.createVertexLabel('Swim', 'id', 'id', 'INT32', false, 'event', 'STRING', false, 'result', 'STRING', false, 'at', 'STRING', false, 'time', 'FLOAT', false)
CALL db.createEdgeLabel('swam','[["Swimmer","Swim"]]')
CALL db.createEdgeLabel('supersedes','[["Swim","Swim"]]')
'''.trim().readLines().each{ run(it) }With these defined, we can create our swim information:
run '''create
(es:Swimmer {name: 'Emily Seebohm', country: '🇦🇺'}),
(swim1:Swim {event: 'Heat 4', result: 'First', time: 58.23, at: 'London 2012', id:1}),
(es)-[:swam]->(swim1),
(km:Swimmer {name: 'Kylie Masse', country: '🇨🇦'}),
(swim2:Swim {event: 'Heat 4', result: 'First', time: 58.17, at: 'Tokyo 2021', id:2}),
(km)-[:swam]->(swim2),
(swim3:Swim {event: 'Final', result: '🥈', time: 57.72, at: 'Tokyo 2021', id:3}),
(km)-[:swam]->(swim3),
(swim2)-[:supersedes]->(swim1),
(rs:Swimmer {name: 'Regan Smith', country: '🇺🇸'}),
(swim4:Swim {event: 'Heat 5', result: 'First', time: 57.96, at: 'Tokyo 2021', id:4}),
(rs)-[:swam]->(swim4),
(swim5:Swim {event: 'Semifinal 1', result: 'First', time: 57.86, at: 'Tokyo 2021', id:5}),
(rs)-[:swam]->(swim5),
(swim6:Swim {event: 'Final', result: '🥉', time: 58.05, at: 'Tokyo 2021', id:6}),
(rs)-[:swam]->(swim6),
(swim7:Swim {event: 'Final', result: '🥈', time: 57.66, at: 'Paris 2024', id:7}),
(rs)-[:swam]->(swim7),
(swim8:Swim {event: 'Relay leg1', result: 'First', time: 57.28, at: 'Paris 2024', id:8}),
(rs)-[:swam]->(swim8),
(swim4)-[:supersedes]->(swim2),
(kmk:Swimmer {name: 'Kaylee McKeown', country: '🇦🇺'}),
(swim9:Swim {event: 'Heat 6', result: 'First', time: 57.88, at: 'Tokyo 2021', id:9}),
(kmk)-[:swam]->(swim9),
(swim9)-[:supersedes]->(swim4),
(swim5)-[:supersedes]->(swim9),
(swim10:Swim {event: 'Final', result: '🥇', time: 57.47, at: 'Tokyo 2021', id:10}),
(kmk)-[:swam]->(swim10),
(swim10)-[:supersedes]->(swim5),
(swim11:Swim {event: 'Final', result: '🥇', time: 57.33, at: 'Paris 2024', id:11}),
(kmk)-[:swam]->(swim11),
(swim11)-[:supersedes]->(swim10),
(swim8)-[:supersedes]->(swim11),
(kb:Swimmer {name: 'Katharine Berkoff', country: '🇺🇸'}),
(swim12:Swim {event: 'Final', result: '🥉', time: 57.98, at: 'Paris 2024', id:12}),
(kb)-[:swam]->(swim12)
'''TuGraph uses Cypher style queries. Here are our three standard queries:
assert run('''
MATCH (sr:Swimmer)-[:swam]->(sm:Swim {at: 'Paris 2024'})
RETURN DISTINCT sr.country AS country
''')*.get('country')*.asString().toSet() == ['🇺🇸', '🇦🇺'] as Set
assert run('''
MATCH (s:Swim)
WHERE s.event STARTS WITH 'Heat'
RETURN DISTINCT s.at AS at
''')*.get('at')*.asString().toSet() == ["London 2012", "Tokyo 2021"] as Set
assert run('''
MATCH (s1:Swim {event: 'Final'})-[:supersedes]->(s2:Swim)
RETURN s1.time as time
''')*.get('time')*.asDouble().toSet() == [57.47d, 57.33d] as SetHere is our traversal query:
run('''
MATCH (s1:Swim)-[:supersedes*1..10]->(s2:Swim {at: 'London 2012'})
RETURN s1.at as at, s1.event as event
''')*.asMap().each{ println "$it.at $it.event" }Apache HugeGraph
Our final technology is Apache HugeGraph.

HugeGraph’s claim to fame is the ability to support very large graph databases. Again, not really needed for this example, but it should be fun to play with. We used a docker image as described in the documentation.
Setup involved creating a client for talking to the server (running on the docker image):
var client = HugeClient.builder("http://localhost:8080", "hugegraph").build()Next, we defined the schema for our graph database:
var schema = client.schema()
schema.propertyKey("num").asInt().ifNotExist().create()
schema.propertyKey("name").asText().ifNotExist().create()
schema.propertyKey("country").asText().ifNotExist().create()
schema.propertyKey("at").asText().ifNotExist().create()
schema.propertyKey("event").asText().ifNotExist().create()
schema.propertyKey("result").asText().ifNotExist().create()
schema.propertyKey("time").asDouble().ifNotExist().create()
schema.vertexLabel('Swimmer')
.properties('name', 'country')
.primaryKeys('name')
.ifNotExist()
.create()
schema.vertexLabel('Swim')
.properties('num', 'at', 'event', 'result', 'time')
.primaryKeys('num')
.ifNotExist()
.create()
schema.edgeLabel("swam")
.sourceLabel("Swimmer")
.targetLabel("Swim")
.ifNotExist()
.create()
schema.edgeLabel("supersedes")
.sourceLabel("Swim")
.targetLabel("Swim")
.ifNotExist()
.create()
schema.indexLabel("SwimByEvent")
.onV("Swim")
.by("event")
.secondary()
.ifNotExist()
.create()
schema.indexLabel("SwimByAt")
.onV("Swim")
.by("at")
.secondary()
.ifNotExist()
.create()While, technically, HugeGraph supports composite keys,
it seemed to work better when the Swim vertex had a single primary key.
We used the num field just giving a number to each swim.
We use the graph API used for creating nodes and edges:
var g = client.graph()
var es = g.addVertex(T.LABEL, 'Swimmer', 'name', 'Emily Seebohm', 'country', '🇦🇺')
var swim1 = g.addVertex(T.LABEL, 'Swim', 'at', 'London 2012', 'event', 'Heat 4', 'time', 58.23, 'result', 'First', 'num', NUM++)
es.addEdge('swam', swim1)Here is how to print out some node information:
var (name, country) = ['name', 'country'].collect { es.property(it) }
var (at, event, time) = ['at', 'event', 'time'].collect { swim1.property(it) }
println "$name from $country swam a time of $time in $event at the $at Olympics"We now create the other swimmer and swim nodes and edges.
Gremlin queries are invoked through a gremlin helper object. Our three standard queries look like this:
var gremlin = client.gremlin()
var successInParis = gremlin.gremlin('''
g.V().out('swam').has('Swim', 'at', 'Paris 2024').in().values('country').dedup().order()
''').execute()
assert successInParis.data() == ['🇦🇺', '🇺🇸']
var recordSetInHeat = gremlin.gremlin('''
g.V().hasLabel('Swim')
.filter { it.get().property('event').value().startsWith('Heat') }
.values('at').dedup().order()
''').execute()
assert recordSetInHeat.data() == ['London 2012', 'Tokyo 2021']
var recordTimesInFinals = gremlin.gremlin('''
g.V().has('Swim', 'event', 'Final').as('ev').out('supersedes').select('ev').values('time').order()
''').execute()
assert recordTimesInFinals.data() == [57.33, 57.47]Here is our traversal example:
println "Olympic records after ${swim1.properties().subMap(['at', 'event']).values().join(' ')}: "
gremlin.gremlin('''
g.V().has('at', 'London 2012').repeat(__.in('supersedes')).emit().values('at', 'event')
''').execute().data().collate(2).each { a, e ->
println "$a $e"
}GraphQL
For the databases we have looked at so far, most support either Gremlin or Cypher as their query language. Another open source graph query language framework that has gained some popularity in recent times is GraphQL. It lets you define graph-based data types and queries and provides a query language. It is often used to define APIs in client-server scenarios as an alternative to REST-based APIs.
While frequently used in client-server scenarios, we’ll explore using this technology for our case study.
graphql-java
The graphql-java library provides an implementation of the GraphQL specification. It lets you read or define schema and query definitions and execute queries. We are going to map those queries to in-memory data structures. Let’s define that data first.
We’ll use records to store our information:
record Swimmer(String name, String country) {}
record Swim(Swimmer who, String at, String result, String event, double time) {}Let’s now create our data structures:
var es = new Swimmer('Emily Seebohm', '🇦🇺')
var km = new Swimmer('Kylie Masse', '🇨🇦')
var rs = new Swimmer('Regan Smith', '🇺🇸')
var kmk = new Swimmer('Kaylee McKeown', '🇦🇺')
var kb = new Swimmer('Katharine Berkoff', '🇺🇸')
var swim1 = new Swim(es, 'London 2012', 'First', 'Heat 4', 58.23)
var swim2 = new Swim(km, 'Tokyo 2021', 'First', 'Heat 4', 58.17)
var swim3 = new Swim(km, 'Tokyo 2021', '🥈', 'Final', 57.72)
var swim4 = new Swim(rs, 'Tokyo 2021', 'First', 'Heat 5', 57.96)
var swim5 = new Swim(rs, 'Tokyo 2021', 'First', 'Semifinal 1', 57.86)
var swim6 = new Swim(rs, 'Tokyo 2021', '🥉', 'Final', 58.05)
var swim7 = new Swim(rs, 'Paris 2024', '🥈', 'Final', 57.66)
var swim8 = new Swim(rs, 'Paris 2024', 'First', 'Relay leg1', 57.28)
var swim9 = new Swim(kmk, 'Tokyo 2021', 'First', 'Heat 6', 57.88)
var swim10 = new Swim(kmk, 'Tokyo 2021', '🥇', 'Final', 57.47)
var swim11 = new Swim(kmk, 'Paris 2024', '🥇', 'Final', 57.33)
var swim12 = new Swim(kb, 'Paris 2024', '🥉', 'Final', 57.98)
var swims = [swim1, swim2, swim3, swim4, swim5, swim6,
swim7, swim8, swim9, swim10, swim11, swim12]These represent our nodes but also the who field in Swim
is the same as the swam edge in previous examples. Let’s represent
the supersedes edge as a list:
var supersedes = [
[swim2, swim1],
[swim4, swim2],
[swim9, swim4],
[swim5, swim9],
[swim10, swim5],
[swim11, swim10],
[swim8, swim11],
]For now, we’ll define a schema using the graphql schema syntax. It will include the details for swims and swimmers, and some queries:
type Swimmer {
name: String!
country: String!
}
type Swim {
who: Swimmer!
at: String!
result: String!
event: String!
time: Float
}
type Query {
findSwim(name: String!, event: String!, at: String!): Swim!
recordsInFinals: [Swim!]
recordsInHeats: [Swim!]
allRecords: [Swim!]
success(at: String!): [Swim!]
}We are now going to define our GraphQL runtime. It will include the schema definition types and query APIs, but also we’ll define providers which define how the data from our data structures is returned for each query:
var generator = new SchemaGenerator()
var types = getClass().getResourceAsStream("/schema.graphqls")
.withReader { reader -> new SchemaParser().parse(reader) }
var swimFetcher = { DataFetchingEnvironment env ->
var name = env.arguments.name
var at = env.arguments.at
var event = env.arguments.event
swims.find{ s -> s.who.name == name && s.at == at && s.event == event }
} as DataFetcher<Swim>
var finalsFetcher = { DataFetchingEnvironment env ->
swims.findAll{ s -> s.event == 'Final' && supersedes.any{ it[0] == s } }
} as DataFetcher<List<Swim>>
var heatsFetcher = { DataFetchingEnvironment env ->
swims.findAll{ s -> s.event.startsWith('Heat') &&
(supersedes[0][1] == s || supersedes.any{ it[0] == s }) }
} as DataFetcher<List<Swim>>
var successFetcher = { DataFetchingEnvironment env ->
var at = env.arguments.at
swims.findAll{ s -> s.at == at }
} as DataFetcher<List<Swim>>
var recordsFetcher = { DataFetchingEnvironment env ->
supersedes.collect{it[0] }
} as DataFetcher<List<Swim>>
var wiring = RuntimeWiring.newRuntimeWiring()
.type("Query") { builder ->
builder.dataFetcher("findSwim", swimFetcher)
builder.dataFetcher("recordsInFinals", finalsFetcher)
builder.dataFetcher("recordsInHeats", heatsFetcher)
builder.dataFetcher("success", successFetcher)
builder.dataFetcher("allRecords", recordsFetcher)
}.build()
var schema = generator.makeExecutableSchema(types, wiring)
var graphQL = GraphQL.newGraphQL(schema).build()We’ll also define an execute helper method which executes a query
using the runtime:
var execute = { String query, Map variables = [:] ->
var executionInput = ExecutionInput.newExecutionInput()
.query(query)
.variables(variables)
.build()
graphQL.execute(executionInput)
}Let’s now look at writing our previous queries.
First, since we have in memory data structures, we’ll acknowledge that it is easy to just write queries using those data structures, e.g.:
swim1.with {
println "$who.name from $who.country swam a time of $time in $event at the $at Olympics"
}But, in a typical client-server environment, we won’t have access to our data structures directly. We’ll need to use the GraphQL API. Let’s do this same query:
execute('''
query findSwim($name: String!, $at: String!, $event: String!) {
findSwim(name: $name, at: $at, event: $event) {
who {
name
country
}
event
at
time
}
}
''', [name: 'Emily Seebohm', at: 'London 2012', event: 'Heat 4']).data.findSwim.with {
println "$who.name from $who.country swam a time of $time in $event at the $at Olympics"
}To find the times for olympic records set in finals, we have a pre-defined query. We can simply call that query and ask for the time field to be returned:
assert execute('''{
recordsInFinals {
time
}
}''').data.recordsInFinals*.time == [57.47, 57.33]We’ll see later how to do this slightly more generically if we didn’t have a pre-defined query.
Similarly, we have a pre-defined query for "At which olympics were records set in heats":
assert execute('''{
recordsInHeats {
at
}
}''').data.recordsInHeats*.at.toUnique() == ['London 2012', 'Tokyo 2021']For "Successful countries in Paris 2024", we have a query that accepts a parameter:
assert execute('''
query success($at: String!) {
success(at: $at) {
who {
country
}
}
}
''', [at: 'Paris 2024']).data.success*.who*.country.toUnique() == ['🇺🇸', '🇦🇺']To "Print all records since London 2012", we use the allRecords query:
execute('''{
allRecords {
at
event
}
}''').data.allRecords.each {
println "$it.at $it.event"
}As an alternative to the recordsInFinals and recordsInHeats queries,
we could have defined a slightly more generic one:
var swimsFetcher = { DataFetchingEnvironment env ->
var event = env.arguments.event
var candidates = [supersedes[0][1]] + supersedes.collect(List::first)
candidates.findAll{ s -> event.startsWith('~')
? s.event.matches(event[1..-1])
: s.event == event }
} as DataFetcher<List<Swim>>Our queries would then become:
assert execute('''{
findSwims(event: "Final") {
time
}
}''').data?.findSwims*.time == [57.47, 57.33]
assert execute('''{
findSwims(event: "~Heat.*") {
at
}
}''').data?.findSwims*.at.toUnique() == ['London 2012', 'Tokyo 2021']The swimsFetcher data provider possibly requires further explanation.
Here, we are explicitly defining a provider that can handle text or regex
(starting with the '~' character) queries. This is because graphql-java
doesn’t provide any filtering out of the box. There are other libraries,
e.g. graphql-filter-java
and graphql-java-filter that provide such filtering,
but we won’t discuss them further here.
GQL
There are various libraries in the Groovy ecosystem related to GraphQL.
Let’s look at GQL which can be thought of as Groovy syntactic sugar over graphql-java.
It makes it easier building GraphQL schemas and execute GraphQL queries without losing type safety.
We first define our schema. Instead of using the GraphQL schema format,
we can optionally define our schema in code. The graphql-java library
also supports this, but with GQL it’s nicer:
var swimmerType = DSL.type('Swimmer') {
field 'name', GraphQLString
field 'country', GraphQLString
}
var swimType = DSL.type('Swim') {
field 'who', swimmerType
field 'at', GraphQLString
field 'result', GraphQLString
field 'event', GraphQLString
field 'time', GraphQLFloat
}Similarly, we can declare our queries and associate the providers:
var schema = DSL.schema {
queries {
field('findSwim') {
type swimType
argument 'name', GraphQLString
argument 'at', GraphQLString
argument 'event', GraphQLString
fetcher { DataFetchingEnvironment env ->
var name = env.arguments.name
var at = env.arguments.at
var event = env.arguments.event
swims.find{ s -> s.who.name == name && s.at == at && s.event == event }
}
}
field('recordsInFinals') {
type list(swimType)
fetcher { DataFetchingEnvironment env ->
swims.findAll{ s -> s.event == 'Final' && supersedes.any{ it[0] == s } }
}
}
field('recordsInHeats') {
type list(swimType)
fetcher { DataFetchingEnvironment env ->
swims.findAll{ s -> s.event.startsWith('Heat') &&
(supersedes[0][1] == s || supersedes.any{ it[0] == s }) }
}
}
field('success') {
type list(swimmerType)
argument 'at', GraphQLString
fetcher { DataFetchingEnvironment env ->
swims.findAll{ s -> s.at == env.arguments.at }*.who
}
}
field('allRecords') {
type list(swimType)
fetcher { DataFetchingEnvironment env ->
supersedes.collect{it[0] }
}
}
}
}As before, to print out information about one swim, we can use the in-memory data structure:
swim1.with {
println "$who.name from $who.country swam a time of $time in $event at the $at Olympics"
}To use GQL, it can look like this:
DSL.execute(schema, '''
query findSwim($name: String!, $at: String!, $event: String!) {
findSwim(name: $name, at: $at, event: $event) {
who {
name
country
}
event
at
time
}
}
''', [name: 'Emily Seebohm', at: 'London 2012', event: 'Heat 4']).data.findSwim.with {
println "$who.name from $who.country swam a time of $time in $event at the $at Olympics"
}This is similar to what we saw with graphql-java, but the runtime
is mostly hidden away.
Our simple queries are also similar to before:
assert DSL.execute(schema, '''{
recordsInFinals {
time
}
}''').data.recordsInFinals*.time == [57.47, 57.33]As an alternative, we can build our queries in code:
assert DSL.newExecutor(schema).execute {
query('recordsInHeats') {
returns(Swim) {
at
}
}
}.data.recordsInHeats*.at.toUnique() == ['London 2012', 'Tokyo 2021']Alternatively, we can build the query as an explicit step:
var query = DSL.buildQuery {
query('success', [at: 'Paris 2024']) {
returns(Swimmer) {
country
}
}
}
assert DSL.execute(schema, query).data.success*.country.toUnique() == ['🇺🇸', '🇦🇺']Printing all records since London 2012 is also very similar to before:
DSL.execute(schema, '''{
allRecords {
at
event
}
}''').data.allRecords.each {
println "$it.at $it.event"
}neo4j-graphql-java
As a final example, let’s look at the support from the neo4j-graphql-java library. It lets you define your
schema as a string like so:
var schema = '''
type Swimmer {
name: String!
country: String!
}
type Swim {
who: Swimmer! @relation(name: "swam", direction: IN)
at: String!
result: String!
event: String!
time: Float
}
type Query {
success(at: String!): [Swim!]
}
'''
var graphql = new Translator(SchemaBuilder.buildSchema(schema))The interesting part is that your can annotate your schema, e.g. the @relation clause for the who field which declares that this
field corresponds to our `swam`edge.
This means that we don’t actually need to define the provider for that field. How does it work? The library converts your GraphQL queries into Cypher queries.
We can execute like this:
var cypher = graphql.translate('''
query success($at: String!) {
success(at: $at) {
who {
country
}
}
}
''', [at: 'Paris 2024'])
var (q, p) = [cypher.query.first(), cypher.params.first()]
assert tx.execute(q, p)*.success*.who*.country.toUnique() == ['🇺🇸', '🇦🇺']We have shown just one of our queries, but we could cover additional queries in a similar way.
Static typing
Another interesting topic is improving type checking for graph database code. Groovy supports very dynamic styles of code through to "stronger-than-Java" type checking.
Some graph database technologies offer only a schema-free experience to allow your data models to "adapt and change easily with your business". Others allow a schema to be defined with varying degrees of information. Groovy’s dynamic capabilities make it particularly suited for writing code that will work easily even if you change your data model on the fly. However, if you prefer to add further type checking into your code, Groovy has options for that too.
Let’s recap on what schema-like capabilities our examples made use of:
-
Apache TinkerPop: used dynamic vertex labels and edges
-
Neo4j: used dynamic vertex labels but required edges to be defined by an enum
-
Apache AGE: although not shown in this post, defined vertex labels, edges were dynamic
-
OrientDB: defined vertex and edge classes
-
ArcadeDB: defined vertex and edge types
-
TuGraph: defined vertex and edge labels, vertex labels had typed properties, edge labels typed with from/to vertex labels
-
Apache HugeGraph: defined vertex and edge labels, vertex labels had typed properties, edge labels typed with from/to vertex labels
The good news about where we chose very dynamic options, we could easily add new vertices and edges, e.g.:
var mb = g.addV('Coach').property(name: 'Michael Bohl').next()
mb.coaches(kmk)For the examples which used schema-like capabilities, we’d need to declare the additional
vertex type Coach and edge coaches before we could define the new node and edge.
Let’s explore just a few options where Groovy capabilities could make it easier to deal
with typing.
We previously used insertSwimmer and insertSwim helper methods. We could supply types
for those parameters even where our underlying database technology wasn’t using them.
That would at least capture typing errors when inserting information into our graph.
We could use a richly-typed domain using Groovy classes or records. We could generate the necessary method calls to create the schema/labels and then populate the database.
Alternatively, we can leave the code in its dynamic form and make use of Groovy’s
extensible type checking system. We could write an extension which
fails compilation if any invalid edge or vertex definitions were detected.
For our coaches example above, the previous line would pass compilation
but if had incorrect vertices for that edge relationship, compilation would fail,
e.g. for the statement swim1.coaches(mb), we’d get the following error:
[Static type checking] - Invalid edge - expected: <Coach>.coaches(<Swimmer>) but found: <Swim>.coaches(<Coach>) @ line 20, column 5. swim1.coaches(mb) ^ 1 error
We won’t show the code for this, it’s in the GitHub repo. It is hard-coded to
know about the coaches relationship. Ideally, we’d combine extensible type checking
with the previously mentioned richly-typed model, and we could populate both the
information that our type checker needs and any label/schema information our
graph database would need.
Anyway, these a just a few options Groovy gives you. Why not have fun trying out some ideas yourself!